Legacy: a hell or an occasion? JBoss to Spring Boot migration story
Contents
- ACT 1 (Un)expected journey – introduction.
- Author’s note.
- ETF Manager world.
- Our (un)expected journey.
- ACT 2 Desolation of the migration – first small microservices migrations.
- Initial configuration.
- JBoss provided services.
- JNDI dependent legacy code.
- ACT 3 Great battle – main monolith migration.
- Configuration cleaning.
- Password management
- Unknown legacy configuration interfering with the Spring Boot libraries.
- Bean without superclass.
- ACT 4 Final encounter – full regression.
- Spring XML configuration problems.
- Transaction manager performance issues.
- Quartz delays.
- Happily ever after
ACT 1 (Un)expected journey – introduction
Author’s note
Many actions took place in parallel. A lot of them were much more complicated than described here. For the sake of the story and to be easier to read small disruptions in the timeline could appear.
At this point I would like to thank all the people who help me finish this article – mainly GFT team members and GFT family leads. But mostly I would like to thank Arek Gasiński for his detailed review of this text and a lot of patience he had for me.
Project Lead: Marcin Radzki
Main Dev: Krzysztof Skrzypiński
QA: Agata Kołuda
Devs: Roman Baranov, Damian Kotynia, Łukasz Kotyński
Our project – ETF Manager – exists forever. At least longer than most of us work here – in GFT. Even longer than my work experience lasts. At a first glance, being here seems like being in exile (which is not on many levels – thanks to other team members, current and past).
ETF Manager world
ETF Manager is about connecting investment banks with ETF market maker and their financial service company. . Because of that ETFM does not have to be the fastest. But it has to be reliable.
As the project lasts forever, most of us joined at different times. Our current lead, Marcin has the longest project experience. Anything that happens here goes through him. Every decision made must be approved by him.
Next is Krzysztof. He is of second greatest seniority. His job is to keep development up with schedules and to make sure everything is ready on time . And not a day later. When there is a challenge to address or a production-issue, he is the first one to act.
The last of ‘the old crew’ is Agata. She must make sure our Jira never gets empty. Every time we finish our tasks she’s on the lookout for the gaps.
Marcin, Krzysztof and Agata have been working with ETF Manager for about seven years now. We – me, Roman, and Damian – are the ‘new crew’ – fresh blood of this project. We have been here for less than three years. Our job is to help keep up this project and make sure it won’t rust.
Our (un)expected journey
As our project matures, a nicer way of saying becomes legacy;), we must stay alert and focus on outdated technologies. Part of our journey is to remove old and insecure stuff and propose something more trendy (jazzy?).
But not only security may lead you to replace some of the elder ones. Old and overcomplicated technology costs its price. It (The previous version of the system) was created as not the easiest thing to maintain – which, in the long run, is the expense as well. This is what led us to make the big decision: We are going to replace JBoss with Spring Boot! Crazy, isn’t it?!
ACT 2 Desolation of the migration – first small microservices migrations
Go Spring Boot they said… But how to start? Migrating from standalone JBoss server to embedded Tomcat does not sound “that” bad. On the other hand, you may look at it as: ‘how to change the foundation of the house?’ Then it looks ‘little bit’ more complex 😉 So how to start doing such ‘fundamental’ change?
Luckily for us, ETFManager has somehow mixed architecture. It has the core module – which is medium size monolith – surrounded by several microservices responsible for communication with the external world. All loosely connected via the AMQ messaging broker.
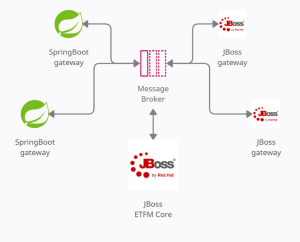
Most of our gateways have been already using Spring Boot. On the other side, two of them have been still working on JBoss. As gateways are relatively simple applications we have chosen them for our experimental site.
Initial configuration
As we already had most of our gateways written in Spring Boot we chose to replicate file and configuration structure as it was there. We made an extra directory that contained all environment-related properties, logging configurations, and running batch/shell scripts.
- gateway
- dist
- application-common.properties
- application-dev.properties
- application-preproduction.properties
- application-prod.properties
- application-sit.properties
- application-support.properties
- application-uat.properties
- bat
- sh
- xml
- logback-dev.xml
- src
- … application code
- build.gradle
- dist
dist is the application’s home directory. Inside there are configuration files
- common, which contains shared configuration
- environment-specific configurations
As all of our environments, besides the development one, save logs to the same Kibana server we have two logging configurations:
- dev – for local development
- common – for every remote environment.
Two script files, i.e., bat and sh are made for ease of commissioning. They contain simple usage and some JAVA_OPTS.
Keeping this configuration with code does not seem to be the best idea but we treat it as a transition stage before dockerizing (containerizing) the app. For now, we prefer to keep running in a unified way with the old applications.
After runtime configuration changes were applied, we moved to the Gradle dependencies. We added spring boot starters and removed unnecessary JBoss or duplicated Spring ones. WAR target was replaced, with the help of the Spring Boot Gradle plugin, by the executable JAR. The custom task for bundling and zipping our `dist` directory was added. The old `compile` dependency configuration was replaced with the new `implementation`. The classic `SpringApplication.run()` was added and voila! We are doing the first test run!
JBoss provided services
No. Of course, it wasn’t that easy. Starting application revealed a few missing bean definitions. All Gateways were connected to external services like DB or Message Broker. When applications were running on JBoss, the Enterprise Server provided configurations for connecting to these services via JNDI. It was so obvious that these services are provided that we almost forgot about their existence. Luckily rewriting them was not that difficult:
- first we had to find all JNDI dependencies injected into the application
- we found them in JBoss configuration by JNDI injections and then we validated their usage in the application by JNDI names
- then we had to provide our connection factories:
- Atomikos for DBs
- RedHat Artemis for AMQ 7
- Lastly, we had to join everything together by our transaction manager – as the previous one was provided by JBoss
With the help of the open-source Atomikos and Spring Data, this small challenge was resolved and connections to messaging brokers were successfully established.
JNDI-dependent legacy code
Still, as I mentioned at the beginning, our application is quite legacy. Providing data sources to the application is one thing. Provisioning external (legacy) libraries with them is another. One of the gateways uses Autex FIX communication. . . And only through JNDI. Quick lookup… in theory, it is not a problem. Tomcat can provide JNDI.
We made the Java configuration with nice and clean loading of beans to JNDI context. Single DataSource was used with JNDI and with other beans. All happy, we did the first test round. After a few unsuccessful tries, Roman found out that… Spring Boot’s Tomcat’s JNDI context is being cleared after context initialization. No direct solution was found. Only to re-write the whole JNDI-dependent code to something more up-to-date.
After even more detailed research and many tears later, deep in the abyss of the internet we found it. Attachable embedded JNDI context. Unluckily, our holy grail turned out to be partially deprecated. One more time brave Roman saved the day by jumping into Spring Code and providing our replacement over crossed-out content. We ended up with our implementation of SimpleNamingContextBuilder and a small JNDI context:
@Bean
@DependsOn( “transactionManager” )
public javax.naming.Context initialJNDIContext(
DataSource dataSource,
UserTransactionManager userTransactionManager
) throws NamingException {
EtfmSimpleNamingContextBuilder builder = new EtfmSimpleNamingContextBuilder();
builder.activate();
JndiTemplate jndiTemplate = new JndiTemplate();
javax.naming.Context ctx = jndiTemplate.getContext();
ctx.bind( “java:comp/env/cust/ETFMDatasourceIM”, dataSource );
ctx.bind( “java:/TransactionManager”, userTransactionManager );
ctx.bind( “java:comp/env/cust/UserTransaction”, userTransactionManager );
return ctx;
}
It worked! Hacky or not we postponed one legacy library re-writing saving some time for the coming battle…
ACT 3 Great battle –migration of the main monolith
After these few successful skirmishes, we started preparing for the main battle – the ETF Manager core (monolith) module. Our recent victories made us trust in our strengths. But the scale of the application increased dramatically. Counting only Java code weight it was like one to twenty. So our legs were trembling. But our hearts were full of faith.
Configuration cleaning
Taught with previous fights, we started with creating configurations and rewriting JBoss provided resources. As we gained some time during gateways re-writing, Damian moved all possible configurations from XMLs to Java, cleaning it as much as possible. Later, we found out that it caused some issues, but it still was a fair price for clean and concise configuration.
Password management
The first wall came at us even before the first start. We hit the first wall even before we were able to warm up – password management. Until now we were using JBoss Vault. JBoss server decommissioning made us require a new vault. Quick investigation – no embedded vaults available. The closest possible solution is HashiCorp Vault. But we wanted to simplify our application and not add more dependencies to be maintained by us. We asked the client if we could use their global vault. Turned out this was the preferred option according to the policies in place.
We started preparing to the vault migration. We did a PoC. We made some requests to access the client vault. A few meetings with the client’s team took place… and we were stuck. For a few months, nothing happened. The client’s company is so big and so many teams had to be involved that our request stuck. And migration date was closer and closer. Luckily Roman saved our day again by providing us with Java Key Store. It was eventually approved as a temporary solution by the client, while waiting for access to the client’s vault.
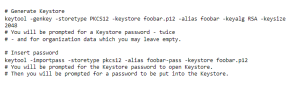
Generating a simple PKCS12 Keystore with some passwords provided looks like this:
Then to use it with java:
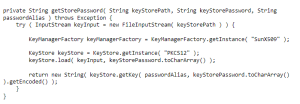
Where example key store usage would be like:
![]()
Unknown legacy configuration interfering with the Spring Boot libraries
First run and next wall. The application was not starting. To make things even more strange, error appeared during Spring class initialization. Spring was fighting itself and we didn’t know why.
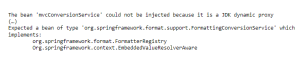
We did web configuration with both Spring Boot and pure Spring style and still – creating proxy error. For a class with no interface, a CGLIB proxy should be generated but for some reason, a pure JDK proxy is forced. What is best – the internet is silent. We felt like children wandering in the fog.
A lot of hours, even more cups of coffee later, few conversations with GFT Big Heads (big thanks to Piotr Gwiazda) followed by some Spring reverse engineering led us to customization of Spring configuration. For some reason, the original Spring class `WebMvcConfigurationSupport` wasn’t working properly with our application. We had to inherit from it and override some default (proxy) settings.
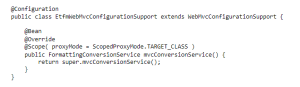
But that was not the only one Spring-related issue.
Bean without superclass
One issue solved made another hit our face.

Spring one more time decided to fail on its own code. Creation of, completely meaningless for us, bean caused application initialization failure. Simple Lambda construct wrapped in a little bit more complex BeanDefinitionBuilder failed. But why?

The answer to this question is relatively simple. Lambda expression is not a fully qualified anonymous class. Because of that, in the reflective world, we had a problem obtaining its interface. There were attempts to bypass this issue, but, unluckily, it doesn’t work with Java higher than 9 (https://github.com/spring-projects/spring-framework/issues/17130). Luckily for us, we found an acceptable solution by overriding the original Spring Bean:
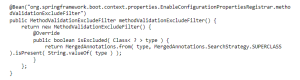
Finally, the long awaited `Started EtfmApplication in …` appeared in the logs! But it wasn’t the end, but rather a short calm before the last storm.
ACT 4 Final encounter – full regression tests
After some fixes here and there, application was ready for Her. Agata – our QA – received the package and started full regression. Every bit of the code was tested. Every path, flow, every process…
But first things first – this whole migration was not done so spontaneously as it could have appeared at the first sight. The application is somehow legacy and it has quite a lot of unit tests. Because our classes didn’t change much, these tests weren’t much of a help. Our second advantage was a relatively big set of integration tests and quite a reliable runbook for important manual work. With such a suit, we started the migration certain that in worst case scenario we would return to the starting point. Production failure wasn’t considered as an option.
Spring XML configuration problems
Most of the functionality worked as expected but some disruptions appeared. Wrong beans were injected in unexpected places. Wrong connections through improper data sources were made. We checked the code many times and everything looked good. There was no place where anything could go wrong. But still, something wasn’t right. Our configuration wasn’t working as expected but started to live its own life.
After a few hours of debugging and comparing the new code with the old one, we found it. As I mentioned before, we re-wrote the XML configuration in Java. It turned out that XML can handle much more than Java. Few configuration classes and autowiring setters were using the wrong class (generic?) types. While XML silently accepted and handled them according to its creator’s wish, Java configuration stood against improper configuration. And unfortunately, some default values were applied instead of supplied ones… SILENTLY!
For the sake of simplicity, let’s consider the following classes:

Someone made a mistake and injected Consumer<String> instead of Consumer<Integer> in the constructor. When using Java annotations, Spring auto-wiring injects the Bar class, and that lead to the RuntimeException:

On the other hand, this problem was not observed in case of the XML configuration:

Because of the type problem we could not solve this issue with just a simple @Qualifier as type mismatch would be detected.
Detecting the problem and fixing the above example is quite simple. But in a real-world scenario with multiple similar beans, it may take a while to realize what happens. Also, bean nesting can make finding issues much harder as the wrong type may be propagated through many nested invocation levels. Still… it is better to be aware of such glitches.
Transaction manager performance issues
As Our application was becoming more and more stable a new enemy appeared – performance issues. First, logging in into the application – under DB loaded with current data – became quite a time-consuming task. Second, on JBoss, executing all background tasks typically took a few seconds. The same thing on Spring Boot could take more than twenty seconds.
Our first steps while investigating these performance issues led us to review what was going on during startup. A quick check of the launch process and it was clear that for hundreds of active user transactions the application was making thousands of DB queries. But still – JBoss simply performed better.
We started checking the configurations of both data sources and connection pools. Some tests for different values were written. But the results were not satisfactory. Earning few seconds could not compare to the speed of JBoss. Eventually, we decided to optimize the loading code. It did its job but we still felt a little bit disappointed. Was it a configuration problem? Or maybe JBoss was doing its job better than the open-source Atomikos?
Quartz delays
But problems with application loading were not the only ones performance-wise. Some of our application’s processes run in the background and are triggered by the Quartz scheduler. But from time to time some of these processes need to be run manually.
Manually triggering an action on JBoss worked instantaneously. Doing the same thing in Spring Boot caused about 20 to 30 seconds delay. But why? From our perspective, it seemed that `nothing` was taking too long. A long pause was happening in the codebase that weren’t our own. And finding external code causing this break was impossible for us as well.
Of course, Google was our first shot. Quick searching found us no solution. But going deeper and deeper we discovered that removing @Transactional from our manual trigger service did the job. So we had the choice: accept the lag or do multiple operations in separate transactions.
Luckily for us, the time was not critical so the first option was chosen but the issue is still awaiting the solution. Is this Spring Boot transaction management-related or maybe Atomikos? Will we be able to tune this behavior? Or maybe it is that the open source versions of the libraries that we use simply perform worse than their paid counterparts?
Happily ever after
Of course, this story does not exhaust all the problems that we faced. We found many other smaller issues on our way which are probably not worth mentioning in this article. Also, Krzysztof and Marcin not only helped us during migration, but what’s more important, they did a great job at shielding us from any external impact. They took on their shoulders the responsibility for negotiations with the client, security scans, and all other ad hoc problems.
Further tests revealed a few other minor problems with the DB connections performance. We applied some tweaks, but still, from time to time, they remind us about themselves in different places in the code. Probably JBoss transactional system simply works better than Open Source Atomikos. Or maybe our Atomikos configuration was not adjusted as well as it could be.
Still, we made it. We pushed it till the end. We decommissioned our JBoss with all of its enormous potential but equally huge infrastructure size and cost. And we replaced it with light and free Spring Boot.
Was it worth it? From one perspective we lost Red Hat commercial support and an incredibly equipped Java Enterprise server. On the other hand, we managed to cut the not so small costs and make our application standalone, which was one of the key steps towards making it cloud-ready. In the short term, it was a lot of work which does not bring any business value to the client. In the long term, it saved the client quite some costs and allowed the project to evolve towards the cloud computing era. And this will definitely make it useful in the coming years.
And the journey itself was rocky but gave us a lot of experience about enterprise application servers as well as standalone Java ones.



