Zero downtime migration of Azure Kubernetes clusters managed by Terraform
Terraform is an awesome tool when it comes to managing your infrastructure as code. You can create complex dependencies between resources in different kinds of cloud and on-prem infrastructure, all with a bunch of .tf files and providers. However, it can often fall flat like a house of cards when you need to change a setting which “forces replacement” of a cornerstone resource, which can result in unwanted downtime and a loss of previously provisioned resources, such as public IP. That should not always be the case though: today we are going to look at a trick that can save you a couple of hours of downtime and quite a few grey hairs.
For me, that kind of resource was Kubernetes cluster and its default node pool, which we run in Azure. As it turns out, when you try to change the size of VMs used by it, your azurerm provider forces you to recreate the whole cluster (together with dependent resources). That is something that you would usually like to avoid doing, especially in production. Even though I will be focusing on the Azure Kubernetes Service in this article, I am positive that you could modify this technique to be usable with other resources as well.
First attempt
Let’s say that your cluster has grown out of some small VMs that you’ve put there in the beginning. The first thing that you’d try to do is change the vm_size in the terraform configuration and apply it. This is when you get the following situation:
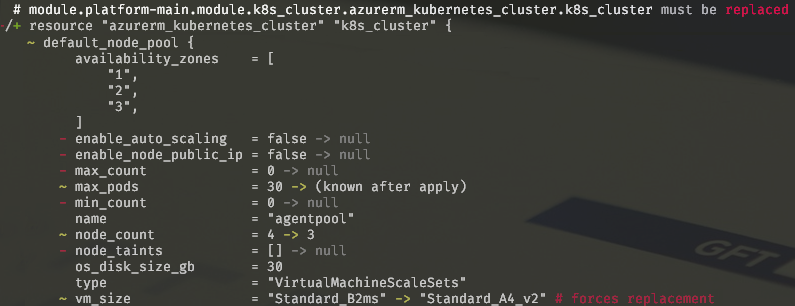
If you are attentive, that is. Otherwise you might have just written “yes” losing your instance together with your deployments, secrets and whatever kind of data you might have been storing there. Also, you might know that Kubernetes clusters are not provisioning very quickly, so we can be looking at a downtime of 1.5-2hrs from my experience.
Moreover, you could have just lost something that was depending on your terraform configuration, like this poor little public IP address:
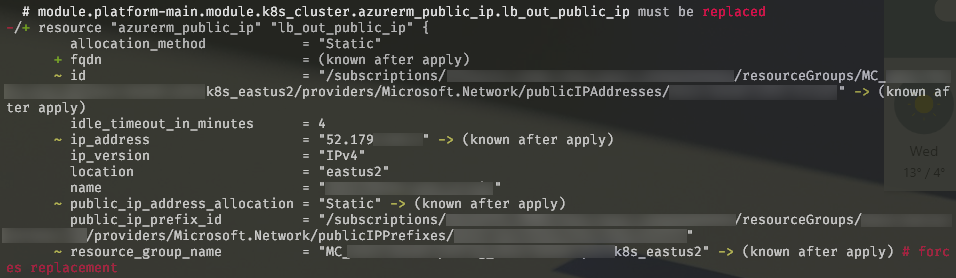
This might cause even more trouble if you have your allow lists unmanaged by terraform, or just have some third parties who explicitly allow your IPs.
There is no way we should tolerate this kind of outages in the modern world where organizations are focused on being available 99.9% of a time. So, let’s see how we can mitigate such an annoyance!
Possible solutions
There are several possible solutions one can apply in order to keep their resources intact. Amongst the most obvious ones are:
- Keep default node pool while creating separate ones of required size,
- Manually migrate to a new node pool using a temporary one.
Both of those options rely on the ability to create non-default node pools in AKS, which is a relatively new AKS feature, so it’s going to be interesting to have a look at how we can use it to our benefit.
Additional pool
The most straightforward solution to this problem is keeping your original node pool while adding some extra pool (or pools) to the mix. It is very easy to implement, given the fact that Azure provider for Terraform can now create separate cluster node pools. This is also very useful because you can add and delete those extra node pools to your heart’s content.
It might not be what you want, however, because System node pools (and the default node pools are System node pools) have certain requirements that they must meet in order to exist [link]:
- System pools osType must be Linux,
- System pools must contain at least one node, and user node pools may contain zero or more nodes,
- System node pools require a VM SKU of at least 2 vCPUs and 4GB memory,
- System node pools must support at least 30 pods as described by the minimum and maximum value formula for pods.
This means that even if you are not using it, you’ll have to leave at least one VM in this node pool and pay for it. Also, it is going to overcomplicate your math when doing monitoring and autoscaling due to VM size differences, especially if you were using burstable instances.
Manual migration
A method that is somewhat more painful, but still preferable if you want to keep your infrastructure simple, is to create a new node pool and move your pods to it, deleting the old one. Let me walk you through the steps needed to achieve it.
Step 1: Create a new Agent Pool
First things first: we need a new agent pool for it to host our pods. I recommend you first get the details of your existing default pool so that when you apply your changes in terraform, the cluster does not get recreated. You can get them by running this command:
> az aks nodepool show –cluster-name $YOUR_CLUSTER_NAME –resource-group $RESOURCE_GROUP_NAME –name agentpool
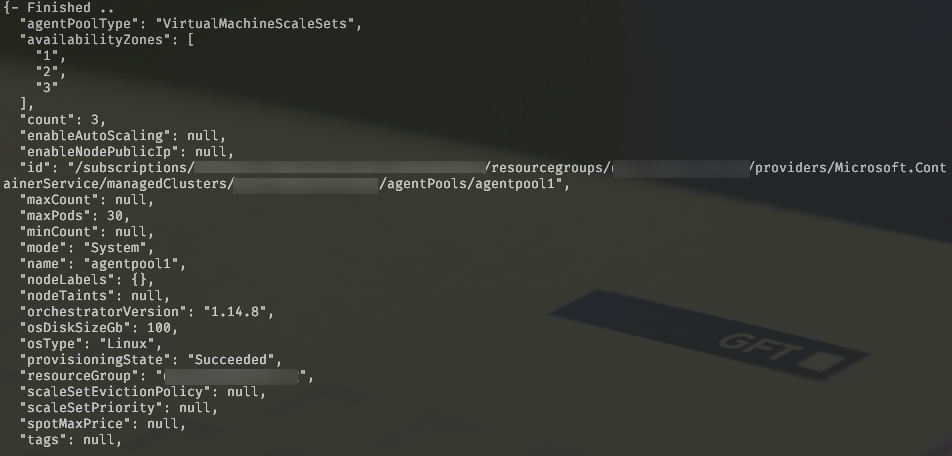
Which is going to produce something like this:
{ "agentPoolType": "VirtualMachineScaleSets", "availabilityZones": [ "1", "2", "3" ], "count": 3, "enableAutoScaling": false, "enableNodePublicIp": null, "id": "******* REDACTED *********", "maxCount": null, "maxPods": 30, "minCount": null, "mode": "System", "name": "agentpool", "nodeLabels": null, "nodeTaints": null, "orchestratorVersion": "1.14.8", "osDiskSizeGb": 30, "osType": "Linux", "provisioningState": "Succeeded", "resourceGroup": "**** REDACTED ****", "scaleSetEvictionPolicy": null, "scaleSetPriority": null, "spotMaxPrice": null, "tags": null, "type": "Microsoft.ContainerService/managedClusters/agentPools", "vmSize": "Standard_B2ms", "vnetSubnetId": "****** REDACTED ******" }
I’ve highlighted with green which properties we need to preserve in order to make this migration seamless. In red there is the value that we are going to change. Coincidentally, most of those values are not changeable while the cluster is running, so you might also use this technique to change the other highlighted values – just remember to update them in terraform.
With those values in mind, we can create a new node pool for the migration:
> az aks nodepool add –cluster-name $YOUR_CLUSTER_NAME -g $RESOURCE_GROUP_NAME -n agentpool1 –node-vm-size Standard_A4_v2 –node-count 3 –mode System -z 1 2 3 –node-osdisk-size 30
You can see that highlighted values are all there, except the one we are going to change (Standard_A4_v2) and the agent pool name. That name is changed because Kubernetes won’t allow us to have multiple pools with the same name. In order to preserve the name, we’re going to repeat the same procedure after we delete the original agentpool. Alternatively, we can change the name in our terraform definition, which should work just fine, unless you have some taints based on the pool name.
Step 2: Cordon & Drain
In order to perform this migration with no downtime at all (or if you have disruption budget specified for your applications) you’d have to have at least two pods of each of your applications at the same time (if it is supported). If you scale up your number of replicas, I recommend using:
> kubectl cordon -l agentpool=agentpool
before changing it. This should prevent pods from being scheduled on our old agentpool.
Now we can evict pods from our old agent pool:
> kubectl drain -l agentpool=agentpool
If your pods don’t use local storage or DaemonSets, this should be enough. In my case, I had to add two more parameters and do the following:
> kubectl drain -l agentpool=agentpool –delete-local-data –ignore-daemonsets
I didn’t find a way to preserve local data, unfortunately, but in the majority of cases it’s going to be just some cache. You should verify this going in, however.
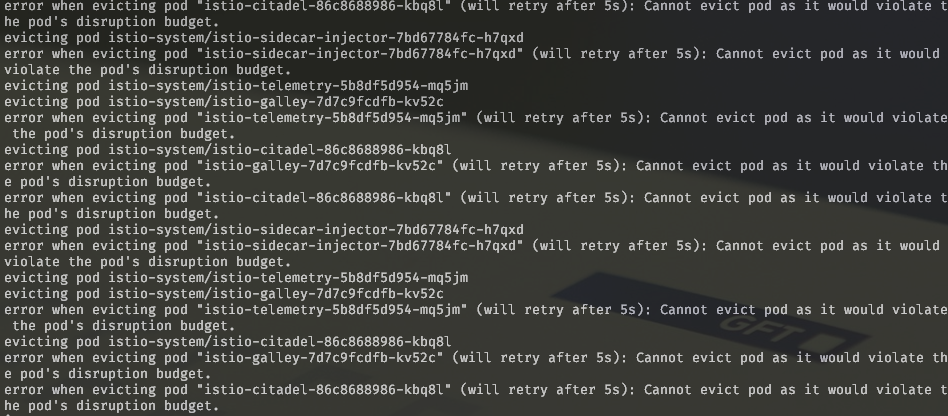
If you still get exceptions like the ones that you see below (from istio in my case), you might need to verify that pods with disruption budget are having enough replicas configured.
Step 3: Delete node pool
Finally, we can delete our old node pool from the cluster:
> az aks nodepool delete –name agentpool -g $RESOURCE_GROUP_NAME –cluster-name $YOUR_CLUSTER_NAME
I was surprised to find out that my continuously running postman test checking liveness of one of the endpoints only failed during this step, even though there were no replicas running for that application:
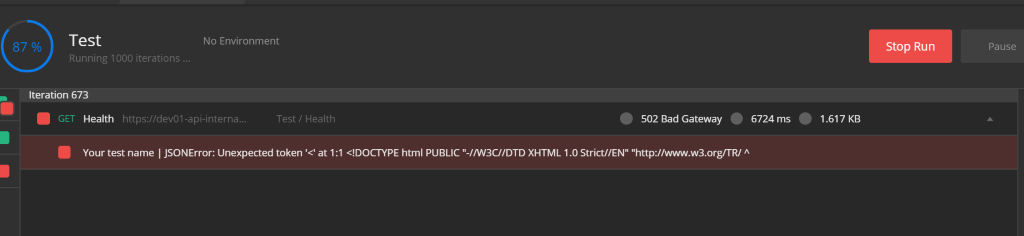
That being the only outage during the whole process, I can say that the migration was quite successful, but we have just a few more things to do.
Step 4: Reimport
There are two ways we can go from here:
- Repeat the steps above to preserve the name of our default agent pool (“agentpool” in my examples),
- Leave it as is (“agentpool1”) and just change it in terraform.
For the purposes of this article, I would go with the second option, which should suffice if you don’t have pool name tolerations set for your pods. You can practice the first option, since it’s basically the same steps, but with different names.
For that to work, we need to update our terraform definitions. You’ll have to find the line that looks like this:

and change the value to “agentpool1” (or some other name that you’ve chosen). If we apply our changes now, however, terraform is going to force recreation of our cluster (so much for all that work!), since an old state is cached and it can’t associate the cluster with our new node pool to what is in the state. We need to reimport our cluster. I like using:
> terraform state list | grep kubernetes_cluster
In order to find out the complete resource name, but if your definitions are rather simple, you can just type the name in. Regardless of which approach you prefer, we should now delete it from the state. Please note that if you have other Kubernetes resources (like namespaces or secrets) created in terraform, you’d need to reimport them as well. When reimporting, take care when specifying the id of the resource – it should be the same as it was in its state previously (terraform is case-sensitive!).
> terraform state rm $K8S_RESOURCE_NAME && terraform import $K8S_RESOURCE_NAME “/subscriptions/$subscriptionId/resourcegroups/$rg_name/providers/Microsoft.ContainerService/
managedClusters/$cluster_name”
After we’ve done this, terraform is going to “get used” to a new node pool and just go with it if we do terraform apply:
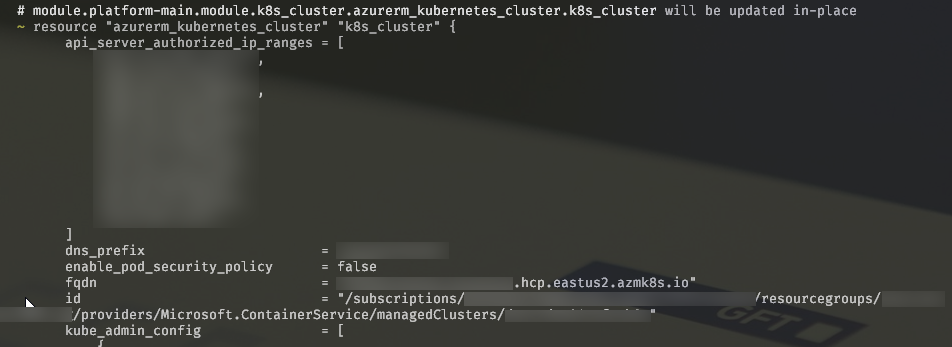
Summary
As we’ve seen, there are different strategies that we can use in order to reduce downtime when upgrading the infrastructure managed by terraform. This might require some manual labor, but when planned properly, you can achieve it. Now that you understand the approach, you can modify it in order to use it for other migrations, such as seamlessly moving your apps running on VMs, databases, etc.


