Techniczne aspekty modelowania hurtowni danych opartej na metodyce Data Vault 2.0
Celem niniejszego artykułu jest szersze spojrzenie na rodzaje obiektów, ich charakterystykę oraz zastosowanie w modelowaniu opartym na metodyce Data Vault 2.0.
Ponadto zobaczymy jaki wpływ na model danych oraz ich segmentację ma domena biznesowa, będąca biznesowym rodzajem metadanych i pewnego rodzaju klasyfikatorem danych.
W dalszej części przyjrzymy się dokładniej aspektom związanym z ładowaniem danych w ramach naszego modelu, w tym koncepcji opartej o tak zwane „hashe” wygenerowane przez funkcję skrótu (z ang. hash function), czyli o tym w jaki sposób opisana metodyka gwarantuje przyrostowe ładowanie danych.
Istota domeny biznesowej i innego rodzaju metadanych w modelowaniu opartym o metodykę Data Vault 2.0
Aby rozpocząć opis charakterystyki i roli metadanych w ramach metodyki modelowania Data Vault 2.0, zdefiniujemy najpierw pojęcie metadanych oraz ich rodzaje.
Metadane są swego rodzaju danymi o danych, które znajdują się w kręgu naszych zainteresowań z punktu widzenia użytkownika biznesowego. Możemy je podzielić na:
- metadane biznesowe
Metadane biznesowe mogą nadawać „naszym danym” warstwę semantyki, dzięki której dokładnie wiemy jakiego rodzaju byty opisują i co dokładnie oznaczają poszczególne atrybuty. Przez byt możemy rozumieć poszczególny rekord.
Takim przykładem metadanych biznesowych jest domena biznesowa.
Domena biznesowa jest splotem informacji, które mówią nam dokładnie jaki wycinek biznesowej rzeczywistości opisują dane (np. ratingi dla obligacji) – zawierając przejście od ogółu do szczegółu oraz dokładną informacje o tym, skąd pochodzą dane. Jest to więc informacja o tak zwanym złotym źródle danych (z ang. golden source). Złotym źródłem może być np. system produkujący dane albo zewnętrzna organizacja (np. agencja Reuters).
Przykładową wartością dla domeny biznesowej może być: „Reuters:Bond:Rating”, która mówi nam, że dany rekord pochodzi ze źródła, którym jest agencja Reuters i dotyczy ratingów dla obligacji.
Domena biznesowa jest ściśle związana z konkretnymi rekordami już na poziomie technicznym podczas tworzenia fizycznego modelu danych, o czym opowiem szerzej w sekcji związanej z ładowaniem danym opartym o hashe.
- metadane techniczne
Metadane techniczne, w odróżnieniu od danych biznesowych, opisują specyfikę dla aspektów technicznych związanych z przetwarzaniem danych. Model danych zaprojektowany z wykorzystaniem metodyki Data Vault 2.0 gromadzi fakty ściśle związane z technicznymi aspektami np. z samym procesem ładowania tych danych, takich jak: czas wstawienia poszczególnych rekordów albo instancja procesu związana z konkretnym ładowaniem. Tego rodzaju techniczne metadane mogę być wykorzystywane na raportach albo do celów związanych z debugowaniem. Podsumowując, mówią nam kiedy i podczas którego ładowania dany rekord pojawił się w tabeli.
Model danych i charakterystyka obiektów w modelu opartym o Data Vault 2.0
Wyobraźmy sobie, że jesteśmy firmą, która jest odpowiedzialna za układanie diety dla klientów. Klienci chcą uzyskać oczekiwaną przez siebie wagę na określonej przestrzeni czasu, w związku z tym firma musi skonstruować odpowiednią dietę, czyli propozycję zestawów na wszystkie posiłki dnia. Poniższy model można zapewne bardziej znormalizować z punktu widzenia normalizacji w Data Vault 2.0, niemniej jednak celem było uniknięcie kompleksowości, która mogłaby spowodować jego znaczne rozszerzenie co do objętości. Na niebiesko oznaczono huby (H), na żółto linki (L), na zielono satelity (S), na fioletowo encję, która przechowuje definicję konkretnych domen.
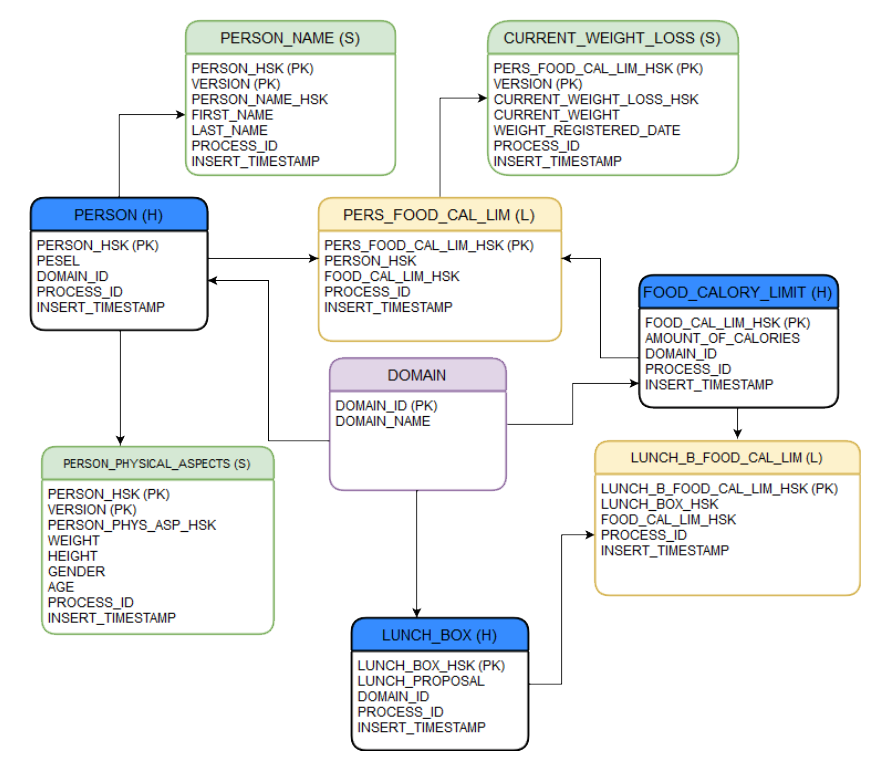
Hub
Istotą hubów jest przechowywanie wyłącznie kolumn będącymi składowymi klucza biznesowego dla rekordu dostarczonego przez złote źródło i sparowanie tego klucza z nowym kluczem wygenerowanym w ramach naszego vaultowego modelu. Klucz taki jest generowany przez funkcję skrótu generującą skrót (hash) w oparciu o wskazany algorytm kryptograficzny. Do produkcji skrótu dla klucza w hubie używa się możliwie długiego co do liczby bitów klucza, po to, by w przypadku małej liczby argumentów zwiększyć szansę na jego unikalność i uniknąć tym samym kolizji hashy, czyli stanu gdzie dla różnych argumentów zostanie wyprodukowany taki sam co do wartości skrót. Jednocześnie staramy się w miarę możliwości ograniczyć czas produkcji skrótu, gdyż takowy będzie liczony dla każdego rekordu, co może znacznie wpłynąć na wydajność procesu. Dobrym wyborem oferującym równowagę między tym aspektami może okazać się algorytm SHA-256 generujący 256-bitowy skrót. Taki klucz w bazie danych Oracle modelujemy jako atrybut typu RAW. Klucze wygenerowane na podstawie funkcji skrótu mają w nazwie sufiks „_HSK”.
Jako argumenty funkcji hashującej przyjmuje się często:
- konkatenację wszystkich kolumn będących składową klucza biznesowego w przypadku, gdy mamy pewność, że dane rekordy napływające z wielu źródeł zdefiniowanych w ramach różnych domen biznesowych (inne domain_id), identyfikują po tej samej wartości klucza biznesowego te same konkretne byty, np. pesel będzie wskazywał zawsze na tę samą osobę, niezależnie z jakiego źródła będzie pochodził rekord.
- konkatenację wszystkich kolumn będących składową klucza, a także nazwy bądź klucza domeny biznesowej. Podejście to stosuje się w przypadku, gdy dane pochodzące z więcej niż jednego źródła nie dają gwarancji, że ta sama wartość klucza w obu źródłach będzie wskazywała na ten sam byt, np. klucze z systemów źródłowych nie są kluczami biznesowymi, a kluczami sztucznymi (z ang. surrogate key).
Hub, oprócz jawnego tłumaczenia klucza biznesowego na klucz w naszym modelu vaultowym, trzyma też referencję do tabeli przechowującej domeny biznesowe, identyfikując tym samym obszar biznesowy i źródło, z którego pochodzi dany rekord. Przechowuje również informacje o instancji procesu, który załadował dany rekord (PROCESS_ID) oraz informacje o czasie jego załadowania (INSERT_TIMESTAMP).
Link
Link jest rodzajem tabeli, która pełni rolę łącznika między dwoma lub więcej hubami. Jest więc odpowiedzialny za zbudowanie relacji między hubami, dając tym samym możliwość zbudowania dowolnej relacji pomiędzy nimi, w tym najmniej restrykcyjnej relacji „wiele do wielu”. Cechą linków jest ich elastyczność i skalowalność, dzięki temu możliwe jest łatwe rozszerzenie modelu w miarę napływu kolejnych wymagań biznesowych. Co najważniejsze, dzieje się to bez przebudowywania istniejącego modelu. Dotyczy to przede wszystkim zmienienia typu relacji (np. z „wiele do wielu” na „jeden do wielu” i na odwrót), co jest uzasadnieniem dla istnienia pośredniej encji, jaką jest link.
Link przechowuje vaultowe klucze (hashe wygenerowane dla poszczególnych kluczy biznesowych każdego z hubów) do hubów, które tworzą relację za pomocą danego linka. Każda kombinacja takich kluczy musi być unikalna. Klucz główny linka tworzy kolejny wygenerowany hash, który za argumenty przyjmuje najczęściej konkatenację kluczy hubów. Dla celów związanych z optymalizacją wydajności można rozważyć mniej złożony algorytm kryptograficzny niż dla hubów, np. MD5. Podobnie jak hub, link przechowuje również informacje o czasie wstawienia rekordu i instancji procesu odpowiedzialnego za jego wstawienie.
Satelita
Huby i linki są rodzajami encji, które przechowują informacje o kluczach i relacjach. Nie ma tam miejsca na atrybuty biznesowe lub atrybuty opisujące szczegółowiej relacje, niebędące jednocześnie składowymi kluczy. Stąd też potrzeba wyodrębnienia innego rodzaju encji, czyli właśnie satelit.
Satelity są bezpośrednio dołączane (jako relacja) to hubów i przetrzymują informacje o biznesowych atrybutach identyfikowanych przez klucz w hubach, dlatego też przechowują również referencje do tychże kluczy. Satelity mogą być również dołączane bezpośrednio (jako relacja) do linków i przechowują atrybuty szerzej opisujące relację pomiędzy hubami zdefiniowaną w tym linku.
Charakterystycznym atrybutem dla satelity jest ich wersja i to ona, w parze z kluczem głównym pochodzącym z huba lub linka, tworzy unikalną parę. Jest to spowodowane tym, że atrybuty biznesowe specyficzne dla satelity, które nie są częścią klucza, mogą zmieniać się w czasie, dlatego dla każdej zmiany choćby jednego atrybutu odkładany jest wersjonowany wpis. Ponadto, satelita przechowuje klucz hashowy dla samej siebie, wygenerowany na podstawie konkatenacji wszystkich atrybutów biznesowych charakterystycznych dla tej satelity. W skład tego klucza nie wchodzą składowe innych kluczy ani żadne atrybuty z rodziny technicznych metadanych. Przykładowo, dla satelity PERSON_PHYSICAL_ASPECTS, klucz hashowy będzie liczony na podstawie konkatenacji kolumn: WEIGHT, HEIGHT, GENDER, AGE. Ze względu na to, że dane biznesowe satelit mogą zmieniać się stosunkowo często i liczba rekordów do zapisania będzie duża, to wystarczającym algorytmem kryptograficznym może okazać się np. MD5. Pozwoli to znacznie poprawić wydajność podczas ich generowania. Satelity, podobnie jak huby i linki, przechowują również techniczne kolumny takie jak instancja procesu, który załadował dany rekord i czas jego wstawienia.
Ważnym aspektem satelit jest to, że dąży się do doprowadzenia do jak największego stopnia granularności jeśli chodzi o obszary biznesowe (pod względem atrybutów, które przechowują). Staramy się pogrupować je w taki sposób, aby atrybuty biznesowe dotyczyły jak najmniejszego wycinka obszaru biznesowego, którego byt (klucz w hubie) opisują. Patrząc na nasz przykładowy model, mamy do czynienia z dwoma satelitami wokół huba PERSON, zamiast tworząc jedną wielką satelitę przechowującą wszystkie atrybuty biznesowe z obu istniejących satelit. Dzięki takiej granularności, nasz model jest bardziej elastyczny i łatwiej o jego rozszerzenie.
Ładowanie danych do modelu Data Vault 2.0
W poprzednich sekcjach wiele razy pojawiły się informacje o kluczach opartych o hashe, ale nie było powiedziane dlaczego właściwie używa się takiego rodzaju podejścia. Ideą tworzenia kluczy liczonych na podstawie funkcji hashowych jest scalenie wartości wielu składowych klucza biznesowego (dla hubów), klucza identyfikującego relację dla par kluczy hubowych (w linkach) i klucza identyfikującego atrybuty biznesowe (dla satelit) do jednej wartości. Taką pojedynczą wartość można porównywać ze sobą w kolejnych procesach zasilających model, a także dalej posługiwać się nią w ramach modelu Data Vault 2.0, np. w linkach możemy przetrzymywać tylko jedną wartość dla każdego z hubów, zamiast wszystkich atrybutów klucza biznesowego, które są brane pod uwagę podczas liczenia klucza w hubach. Dzięki jednej wartości dla pojedynczego rekordu, jednoznacznie go identyfikującego w danym aspekcie, możemy określić przy kolejnych procesach ładujących czy dany rekord już istnieje (został załadowany w przeszłości) i nie ładować go w bieżącym procesie. Na tym polega idea kluczy hashowych: chcemy porównywać je i zapewnić tym samym przyrostowe ładowanie danych do modelu. Tylko nowe wartości kolumn opartych o hashe są brane pod uwagę. Dzięki temu znacznie oszczędzamy miejsce na dysku, na którym dane te są składowane i nie ma potrzeby rozszerzenia klucza głównego o dodatkową kolumnę jaką jest PROCESS_ID.
Jedynym, aczkolwiek bardzo mało prawdopodobnym mankamentem związanym z generowaniem hashy jest sytuacja, gdy dla dwóch lub więcej różnych zestawów wejściowych (argumentów), funkcja skrótu wygeneruje dwie identyczne wartości wyjściowe. Jest to tak zwana kolizja hashy, która naturalnie komplikuje sytuację, gdyż zależy nam na unikalności tych wartości. Niemniej jednak prawdopodobieństwo tego zdarzenia jest bardzo niskie i zależy od dwóch czynników: złożoności algorytmu kryptograficznego (im większa liczba bitów na wyjściu, tym mniejsza szansa) i liczby rekordów, dla których będzie liczony skrót (im większa liczba zestawów wejściowych, tym większa szansa). Dla przykładu dla około 192 milionów rekordów, dla których będzie liczony hash w oparciu o MD5 (64 bitowy skrót) prawdopodobieństwo kolizji hashy to 0,001. To samo prawdopodobieństwo dla SHA-1 (160 bitowy skrót) ma miejsce dopiero dla 5,51×1022 różnych wierszy, dla których będzie liczony hash[1]. Jest to ryzyko znane i akceptowalne w większości modeli opartych o Data Vault 2.0.
Jeśli chodzi o aspekty organizacyjne, to taka struktura modelu wymusza oczywiście kolejność ładowania poszczególnych rodzajów obiektów w modelu Data Vault 2.0. W pierwszej kolejności ładowane są równolegle wszystkie huby, następnie równolegle wszystkie linki, a na samym końcu satelity. Jest to oczywiście wymuszone podstawowymi zależnościami między obiektami, między którymi istnieje integralność referencyjna. Relacja tabel „parent-child” wymusza najpierw załadowanie tabel, których klucze główne łączą się z kluczami obcymi w tabelach typu child.
Podsumowanie
Modelowanie danych opartych o metodykę Data Vault 2.0 umożliwia szybsze i elastyczniejsze rozbudowanie istniejącego modelu. Co ważne, podejście w wersji 2.0 zapewnia również przyrostowe ładowanie danych w oparciu o hashe, co jest niewątpliwie dużym plusem. Ideą takiego podejścia jest również pełna transparentność jeśli chodzi o pochodzenie danych, czas ich pojawienia się oraz sposób przetwarzania, co definiuje nam cykl ich życia (z ang. data lineage). Taka metodyka zapewnia dobrą skalowalność w przypadku, gdy mamy do czynienia z kilkoma różnymi źródłami danych dostarczających dane o bytach z tego samego wycinka rzeczywistości biznesowej.

