Data Vault 2.0 jako nowa metodyka projektowania i implementowania hurtowni danych
Czy Data Vault 2.0 jest właściwą odpowiedzią na dzisiejsze wymagania dotyczące procesowania, analizowania oraz raportowania danych? Jak metodyka ta wpisuje się w istniejące rozwiązania? W naszej nowej serii artykułów chcielibyśmy odpowiedzieć na te pytania oraz przedstawić czym jest DV i jak przy jego użyciu zaprojektować można hurtownię danych z zachowaniem najlepszych praktyk.
Czym jest Data Vault 2.0?
Data Vault 2.0 jest czymś więcej niż tylko nowoczesnym sposobem modelowania danych. To metodyka, która podpowie nam w jaki sposób zaimplementować hurtownię danych spełniającą wyśrubowane wymagania współczesnego biznesu. Co więcej, uwzględnia ona dobre praktyki tworzenia i utrzymywania hurtowni danych w obszarach: modelowania danych, architektury, samej metodyki prowadzenia projektu oraz implementacji.
Już na wstępie warto zaznaczyć, że DV 2.0 w swojej budowie jest podejściem, które charakteryzuje się dużym naciskiem na audyt oraz śledzenie danych ładowanych z wielu źródeł. Jest to elastyczna struktura, które pozwala w łatwy sposób rozszerzać hurtownie danych o nowe dane lub całe obszary, jak i implementować niezbędne zmiany biznesowe.
W artykule objaśnię najważniejsze komponenty architektury i modelu DV 2.0, które bardziej szczegółowo przybliżymy w kolejnym tekście. Następnie przyjrzymy się metodyce prowadzenia projektu, uwzględniając plusy i minusy stosowania DV 2.0 w projektach komercyjnych.
Architektura
Trójwarstwowa architektura pełnego rozwiązania została zaprezentowana na rysunku 1 i składa się z trzech głównych warstw:
- Staging, gdzie ładowane są dane surowe z innych systemów,
- Warstwa hurtowni danych (Enterprise Data Warehouse), z różnymi obszarami Vaulta,
- Warstwa informacji (Information Delivery) – zawierająca Information Marts, zamodelowane w sposób zrozumiały dla użytkownika końcowego, np. wykorzystując modele wielowymiarowe.
Na wspomniane trzy warstwy składają się takie obszary jak:
- Staging – tak jak w innych podejściach, głównym celem tego obszaru jest jak najszybsze wyładowanie danych z systemów źródłowych, tak, aby powodować jak najmniejsze ich obciążenie. Proces powinien na tym etapie unikać jakichkolwiek transformacji. Struktura danych powinna jak najwierniej odzwierciedlać strukturę oryginalnych danych, z uwzględnieniem metadanych audytowych takich jak: znaczniki czasowe, źródło danych itp.
- Warstwa hurtowni danych (EDW)
- Raw Data Vault – warstwa hurtowni danych, która, jak sama nazwa wskazuje, ma na celu trzymanie danych surowych, które ładowane są ze obszaru Staging. Dane te są najczęściej poddane niewielkim transformacjom (tzw. hard business rules), takim jak normalizacja, uzupełnienie wartości domyślnych lub uspójnienie typów danych. Struktura tej warstwy tworzona jest zgodnie z zasadami modelowania w DV 2.0 (o czym poniżej).
- Metrics Vault – opcjonalny obszar, który rozszerza warstwę hurtowni danych o możliwość przechowania informacji o procesie i poszczególnych uruchomieniach z uwzględnieniem metadanych procesowych oraz wszelkiego rodzaju metryk technicznych, takich jak: liczba załadowanych wierszy, liczba wierszy odrzuconych czy czas ładowania itp.
- Operational Vault – opcjonalny obszar, będący rozszerzeniem warstwy hurtowni danych o miejsce, które udostępnia dane (do odczytu jak i zapisu) potrzebne dla systemów operacyjnych (Operational Systems), takich jak Master Data Management (MDM). Dzięki temu systemy tego typu mogą mieć dostęp bezpośrednio do warstwy hurtowni danych i nie muszą korzystać z obszaru Staging lub Information Marts. Dodatkowo do Operational Vault mogą mieć dostęp systemy wykorzystujące dane surowe do różnego rodzaju analiz, np. wykorzystujące algorytmy eksploracji danych (data mining) oraz systemy potrzebujące danych w czasie rzeczywistym.
- Business Vault – kolejny opcjonalny obszar, który nie jest osobną warstwą, a rozszerzeniem warstwy hurtowni danych, gdzie dane pobierane z Raw Data Vault poddane są transformacji poprzez zastosowanie reguł biznesowych (tzw. soft business rules). Reguły te, w odróżnieniu od ich twardych odpowiedników, transformują dane zgodnie z wymaganiami biznesowymi. Business Vault jest elementem pośrednim pomiędzy Raw Data Vault a Information Marts, który ułatwia późniejsze transformowanie danych do struktur, z których będą korzystać użytkownicy końcowi. Z założenia użytkownicy nie mają dostępu do Raw Data Vaulta, natomiast tzw. power users, którzy potrafią posługiwać się językiem SQL oraz modelami relacyjnymi, mogą mieć dostęp do Business Vaulta.
- Information Marts (ID) – warstwa stworzona dla użytkowników końcowych, w której przechowuje się dane przetransformowane do postaci zrozumianej przez użytkowników oraz aplikacje. Nazwa Information Marts została użyta przez twórców DV 2.0 nieprzypadkowo – ma podkreślać, że w odróżnieniu od Data Marts, w tym obszarze operujemy już na informacjach, czyli danych, które są dedykowane dla danego obszaru biznesowego, wyczyszczone, przetransformowane z zastosowaniem reguł biznesowych (soft business rules) oraz potencjalnie zagregowane. Innymi słowy, przygotowane pod raportowanie. Information Marts są często zbudowane jako Star Schema, czyli model, który dobrze współpracuje z oprogramowaniem do raportowania. Warstwa ta uwzględnia również takie obszary jak:
- Error Mart – informacje dotyczące błędów, odrzuconych rekordów, złamanych reguł biznesowych
- Meta Mart – wszelkiego rodzaju metadane.
W odróżnieniu od innych Information Martów, Error Mart oraz Meta Mart nie może być odtworzony z danych surowych (Raw Data Vault).
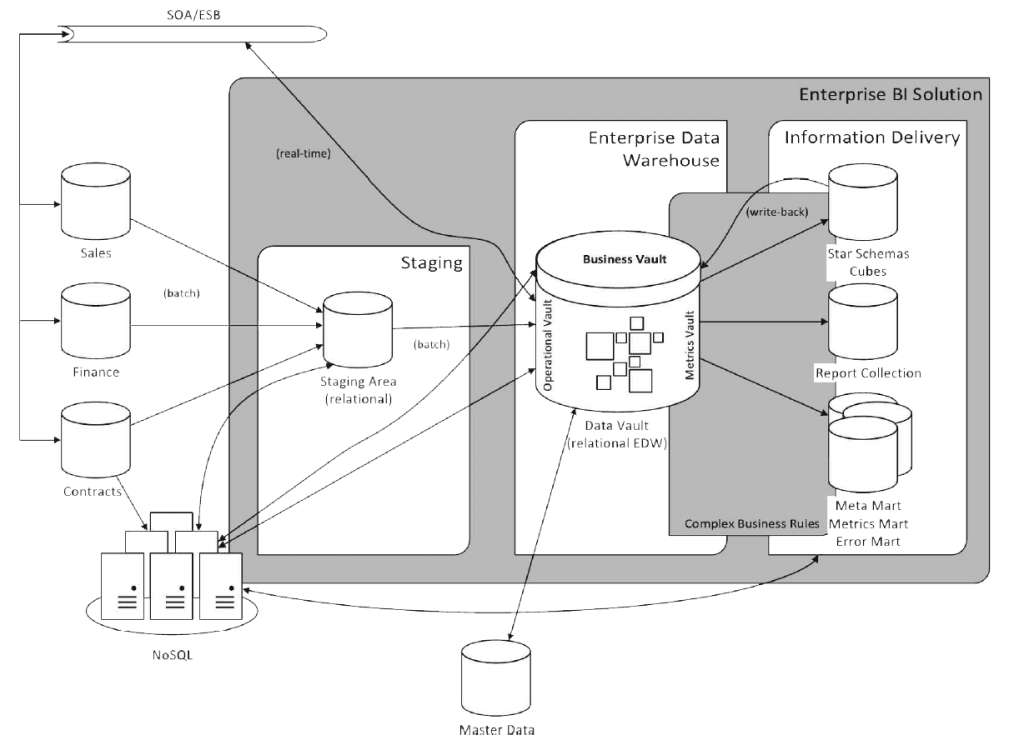
Rysunek 1: Architektura Data Vault 2.0
(źródło: „Building a Scalable Data Warehouse with Data Vault 2.0” M. Olschimke, D. Linstedt)
Modelowanie struktur zgodnie z DV 2.0
Jak wspomniano powyżej, DV 2.0 to coś więcej niż tylko model, natomiast jego główną zaletą jest struktura w jakiej dane są przechowywane – stanowi to trzon całej koncepcji.
Przykładowy model oraz relacja zostały zaprezentowane na poniższym obrazku:

W uproszczeniu, głównymi rodzajami encji w DV 2.0 są:
- Huby – przechowują klucze biznesowe encji, np. identyfikatory,
- Linki – przechowują relację pomiędzy obiektami poprzez połączenie dwóch lub więcej Hubów,
- Satelity – niosą ze sobą dodatkowe atrybuty opisujące dany obiekt (połączone z Hubem) lub relację (połączone z Linkiem).
Są to jedynie podstawowe rodzaje obiektów wykorzystywane w DV. Ponadto, każdy z nich przechowuje odpowiednie metadane. Wymienione wyżej obiekty posiadają swoje podrodzaje oraz związane z nimi pojęcia, które zostaną wyjaśnione w następnym artykule.
Korzystając z rysunku nr 2 jako prezentacji rodzajów obiektów, skupmy się na zrozumieniu przykładowego modelu, który opisuje już realny przypadek biznesowy:
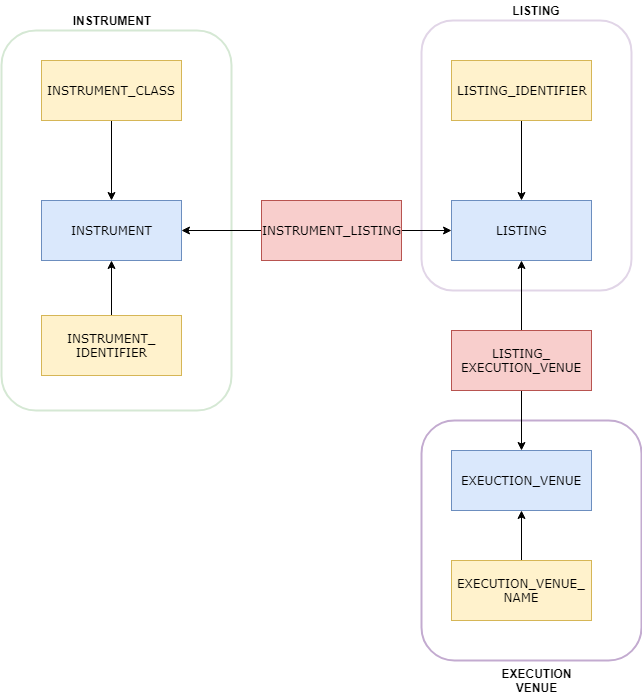
Jak widać, mamy tu kilka obszarów tematycznych połączonych ze sobą na linkami:
- Instrument – obszar opisujący instrumenty finansowe,
- Execution Venue – obszar opisujący rynek finansowy,
- Listing – obszar opisujący Listing danego instrumentu, czyli występowanie danego instrumentu na rynku finansowym (np. na giełdzie).
Jest to uproszczony model opisujący świat instrumentów finansowych. Nazwy encji zdają się być deskryptywne, ale dla porządku opisałem je poniżej:
- INSTRUMENT – zawiera klucz biznesowy instrumentu – identyfikator,
- INSTRUMENT_IDENTIFIER – zawiera alternatywne identyfikatory instrumentów, np. ISIN, CUSIP,
- INSTRUMENT_CLASS – zawiera informacje o klasie, do której dany instrument należy (np. REIT),
- INSTRMENT_LISTING – łączy instrument z listingiem,
- LISTING –zawiera klucz biznesowy listingu,
- LISTING_IDENTIFIER – identyfikator listingu (instrumentu na poziomie rynku), np. RIC, SEDOL,
- LISTING_EXECUTION_VENUE – łączy informacje o listingu z rynkiem,
- EXECUTION_VENUE –zawiera klucz biznesowy rynku finansowego,
- EXECUTION_VENUE_NAME – zawiera deskryptywną nazwę rynku finansowego.
Wyobraźmy sobie następującą sytuację: dany model chcemy rozszerzyć o nowy obszar zawierający informacje o produktach finansowych. Wiemy, że dany produkt jest powiązany z instrumentem. Czy musimy zmieniać istniejący model? Niekoniecznie – wystarczy, że nowy obszar dołączymy do naszego modelu za pomocą obiektu typu Link (INSTRUMENT_PRODUCT):
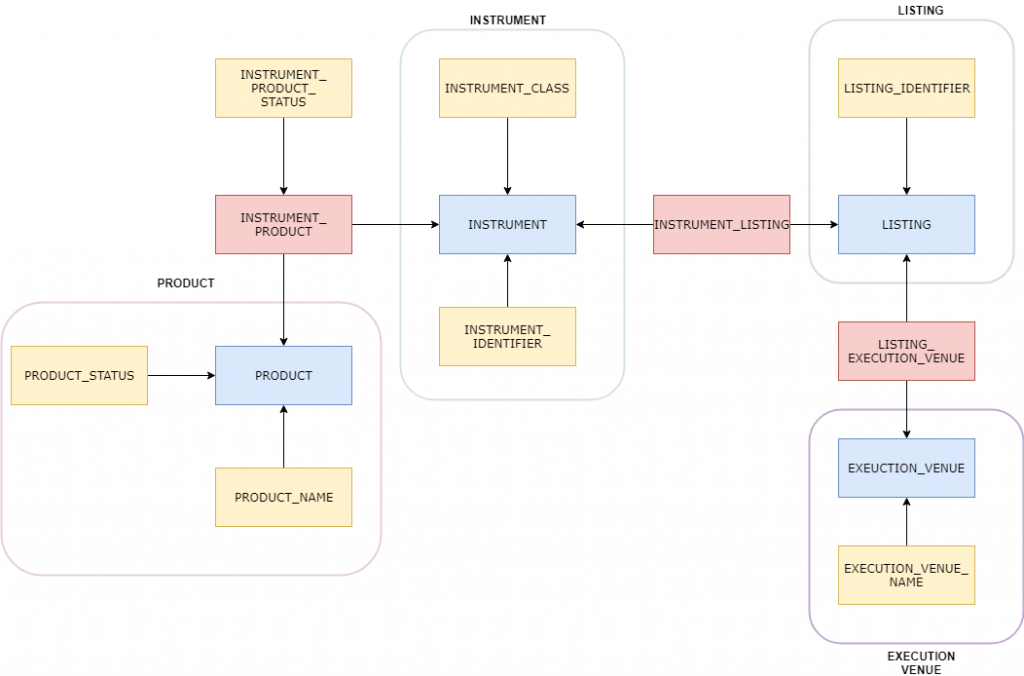
Rysunek 4: Model instrumentów z uwzględnieniem produktów
Jak wspominałem wyżej, encje typu Satelity mogą opisywać zarówno Huby jak i Linki. Czym innym jest PRODUCT_STATUS, który dostarcza informacji o statusie danego produktu (produktu o danym kluczu biznesowym), a czym innym INSTRUMENT_PRODUCT_STATUS, który mówi nam o stanie relacji produktu z instrumentem (połączenia dwóch kluczy biznesowych). Może zdarzyć się sytuacja, że zarówno produkt jak i instrument jest aktywny, natomiast dany instrument nie jest już kojarzony z danym produktem.
Kimball vs Inmon vs Data Vault
Zajmijmy się jeszcze jednym aspektem nowego modelu i całej metodyki implementacji hurtowni danych: jak DV 2.0 wpisuje się w istniejące od lat rozwiązania?
Ralph Kimball oraz Bill Inmon zaproponowali swoje rozwiązania już kilkadziesiąt lat temu i stanowiły one trzon ówczesnych hurtowni danych. W różnych źródłach można znaleźć mnóstwo recenzji tych podejść, jak i ich porównań. Gdzie zatem w tym kontekście wpisuje się Data Vault? Żeby odpowiedzieć na to pytanie, musimy zrozumieć co tak naprawdę chcemy porównać – same modele czy całe metodyki.
Jest to o tyle ważne, że jak twierdzi sam twórca Data Vaulta, Dan Linstedt, Corporate Information Factory (CIF) Inmona oraz Kimball Architecutre BUS są frameworkami architektonicznymi, które mówią nam co powinniśmy mieć w hurtowni danych, natomiast Data Vault Methodology podpowie nam jak mamy to zaimplementować.
Jak widać, jest tu wiele aspektów, które należałoby wziąć pod uwagę, jednak analizując rozwiązania bardzo ogólnie, można pokusić się o stwierdzenie, że Data Vault jest bardziej zbliżony do CIFa proponowanego przez Inmona. Tutaj również mamy do czynienia z 3-warstwową architekturą, a jedynie Data/Information Marty są zbudowane używając struktur wielowymiarowych. Co zatem różni te dwa podejścia? Wg Linstedta zasadniczą różnicą jest to, w którym momencie stosujemy reguły biznesowe. W podejściu Inmona dane, które są ładowane do obszaru ODS (Operational Data Store), który stanowi trzon tej architektury, są już wyczyszczone oraz przetransformowane. Natomiast w DV 2.0, te operacje zostawiamy na sam koniec procesowania, ładując dane do Business Data Vaulta lub też obszaru Information Mart.
Warto również nadmienić, że CIF ewoluował (uwzględniając dzisiejsze potrzeby) w DV 2.0 i ta różnica zanika. Wg Linstedta sam Bill Inmon stwierdził:
“The Data Vault is the optimal choice for modeling the EDW in the DW 2.0 framework.”
Z kolei, jeżeli chcielibyśmy porównać omawiane rozwiązanie z podejściem Kimballa, to musielibyśmy się skupić m. in. na porównaniu proponowanych modeli: modelu użytego w DV 2.0 oraz Star Schema. Jest to jednak na tyle obszerny temat, że należałoby temu poświęcić osobną analizę.
Podsumowanie
Data Vault 2.0 ma na pewno wiele zalet, m.in. wyjątkowo elastyczną strukturę, która umożliwia adaptowanie nowych wymagań biznesowych oraz dołączanie dodatkowych obszarów do hurtowni w sposób relatywnie szybki i niewymagających dużych zmian w istniejącej strukturze. Dodatkowo, metadane, które są trzymane wraz z danymi biznesowymi oraz fakt, iż transformacja danych przy użyciu tzw. miękkich reguł biznesowych odbywa się na końcu procesu, ułatwia audyt danych oraz umożliwia spełnienie wymagań takich jak śledzenie zmian (traceability). Ponadto, z technicznego punktu widzenia, elastyczność struktur przechowujących dane w DV 2.0 umożliwia stworzenie generycznych mechanizmów ładowania danych oraz automatyzację całego procesu.
Z drugiej strony wydaje się, że jest niewiele programów do zarządzanie hurtownią danych oraz wspomagających raportowanie, które w pełni wspierają model DV. Wymusza to dodanie dodatkowej warstwy, która przetransformuje Raw lub Business Data Vault do postaci rozumianej przez użytkownika końcowego i/lub aplikację – co oczywiście nie jest złą praktyką, nie mniej w tym podejściu nie mamy innego wyjścia.
Podsumowując, sama koncepcja wydaje mi się bardzo atrakcyjna. Dzięki swoim zaletom, Data Vault 2.0 bardzo dobrze wpisuje się w potrzeby Data Governance, które zdają się być kluczowe w dzisiejszym świecie – zwłaszcza w kontekście regulacji, którą muszą spełnić instytucje finansowe. Biorąc pod uwagę choćby regulację BCBS 239, która wprost mówi o prawidłowym definiowaniu, zbieraniu oraz zarządzaniu danymi związanymi z ryzykiem, z uwzględnieniem takich pryncypiów jak: accuracy, integrity, completeness, timeliness oraz adaptability, DV 2.0 zdaje się być rozwiązaniem, które może pomóc spełnić te wymagania. Naturalnie wciąż jest to tylko (i aż) narzędzie, a o tym, czy powyższe zasady lub dobre praktyki zostaną spełnione, decydują ludzie – zaczynając od wysokopoziomowego Data Management, aż po dostarczanie poszczególnych rozwiązań.
Źródła
- M. Olschimke, D. Linstedt: Building a Scalable Data Warehouse with Data Vault 2.0, 2016
- https://blog.westmonroepartners.com/data-warehouse-architecture-inmon-cif-kimball-dimensional-or-linstedt-data-vault/
- https://www.talend.com/blog/2015/03/27/what-is-the-data-vault-and-why-do-we-need-it/
- http://danlinstedt.com/
- http://tdan.com/data-warehouse-design-inmon-versus-kimball/20300
- https://www.ismll.uni-hildesheim.de/lehre/bi-10s/script/Inmon-vs-Kimball.pdf
- http://www.vertabelo.com/blog/technical-articles/data-vault-series-the-business-data-vault
- https://www.slideshare.net/dlinstedt/data-vault-and-dw20

