Qlik Sense. Go for it! – część 2
W kolejnej części naszej przygody z Qlik Sense omówimy, w jaki sposób stworzyć prostą aplikację za pomocą podstawowych komponentów narzędzia. Wskażemy też, jak produkt sprawdza się przy rzeczywistym wdrożeniu, w którym operujemy na bardzo dużej ilości danych.
W poprzednim artykule udało nam się zauważyć potrzebę bezpośredniego wglądu w dane przez użytkownika. Może to być utrudnione z uwagi na czas potrzebny na analizę i wytwarzanie oprogramowania przez zewnętrzne zespoły deweloperskie. Wskazaliśmy również, że Qlik Sense, jako rozwiązanie Business Intelligence, z definicji umożliwia użytkownikowi samodzielne zestawienie dostępu do danych i ich wizualizację. Zobaczmy, jak się do tego zabrać.
Strona GFT
Posłużymy się dla przykładu naszą firmową stroną internetową, na której znajdziemy aktualne wyceny akcji spółki GFT, z uwzględnieniem największych giełd w Niemczech. Dane pozyskiwane są w postaci plików json i przedstawiane w formie tabeli oraz wykresu. My również posłużymy się tą informacją, jako źródłem danych do naszej aplikacji.
Nie będziemy poświęcać zbyt wiele miejsca na szczegóły powstawania aplikacji, a jedynie zarysujemy ogólne etapy. Dla osób, które chciałyby bliżej przyjrzeć się omawianym przykładom, kod źródłowy udostępniony został na GitHub.
Aplikacja w Qlik Sense
Qlik Sense może być używany jako aplikacja desktopowa (darmowa także do wykorzystania komercyjnego!) lub w postaci rozwiązania webowego, dla wersji Enterprise / Cloud. W naszym przykładzie posłużymy się wersją desktop.
Dla ścisłości dodam, że uruchamiając wersję desktop, w rzeczywistości używamy wersji z lokalnym serwerem. Wszystkie kontrolki i komponenty utworzone są w HTML i serwowane przez serwer HTTP, podczas gdy „gruby klient” tylko je renderuje. Dzięki temu, możemy sprawdzić jak nasza aplikacja wygląda w postaci przeglądarkowej. W tym celu należy zbudować z nich tzw. mash-up, jak ten poniżej.
Development polega na stworzeniu aplikacji w samym Qlik Sense, a następnie utworzeniu w nim arkuszy. I tu pojawia się pierwszy zgrzyt ze standardowym podejściem, ponieważ aplikacja zwykle jest czymś, co tworzą deweloperzy – powinna przejść testy i trafić na środowisko produkcyjne. Jak zatem wdrożyć coś, co zostało jedynie „wyklikane” w samym Qlik Sense i funkcjonuje w jego trzewiach?
Ale czym tak naprawdę jest plik Excela? Czy nie jest to aplikacja, która ma w sobie arkusze, a w nich tabelki, wykresy oraz zagnieżdżone makra? Co więcej, plik zawiera też dane, które są jego częścią i stanowią właściwą treść pliku. Ta analogia doskonale opisuje aplikację Qlik Sense. Jeśli wyeksportujemy ją z instancji QlikSensa, otrzymamy plik w formacie QVF – a ten może być ponownie zaimportowany na dowolne środowisko SIT, UAT czy PROD.
Kontrolki
Posługując się analogią do Excela, użytkownik ma do dyspozycji wiele kontrolek, takich jak listy, wykresy i tabelki. Może je swobodnie przeciągać na swój arkusz. Domyślnie jest ich kilkanaście, ale bogata społeczność Qlik Sense oferuje bardzo wiele dodatkowych komponentów.
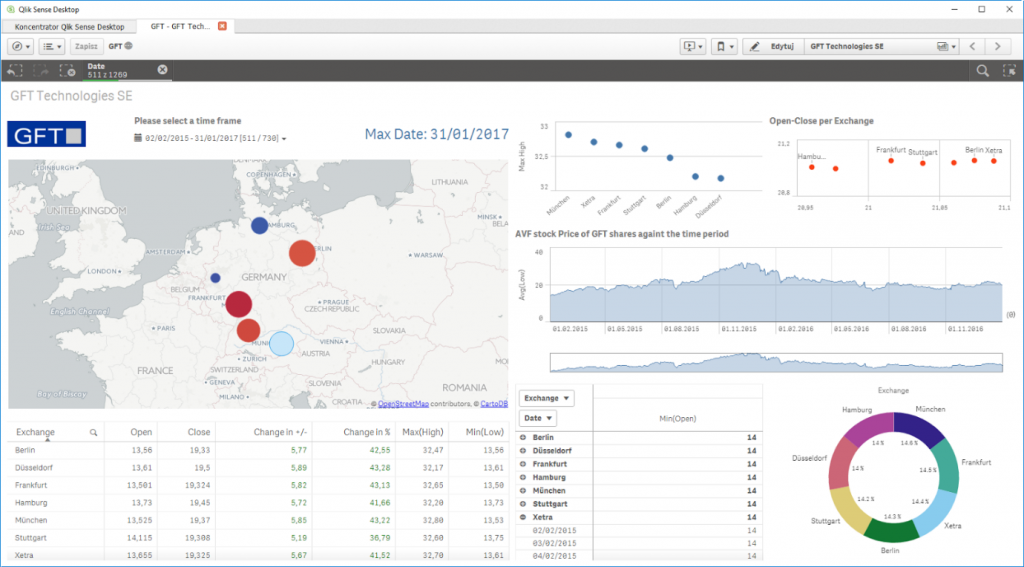
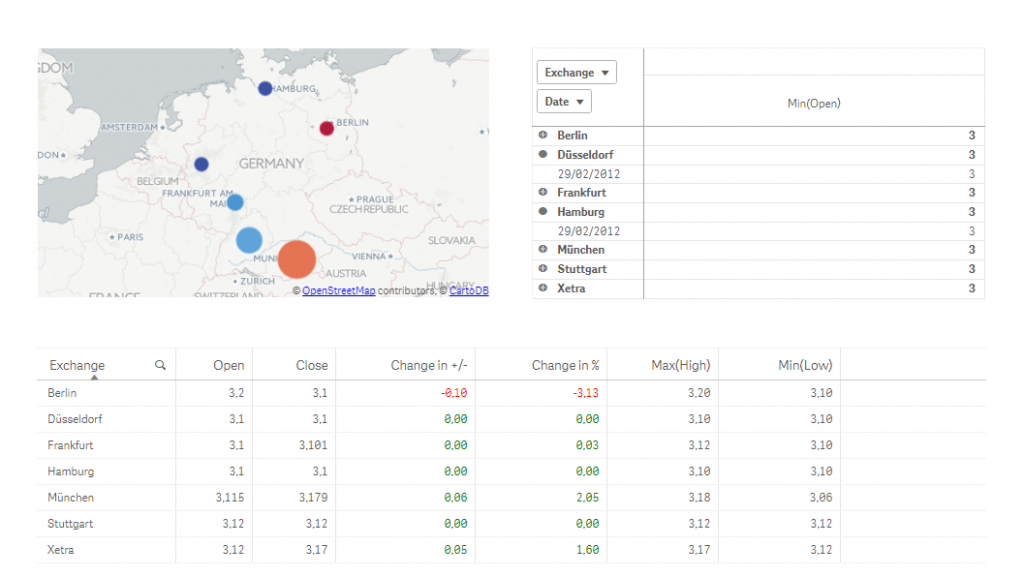
W tym miejscu chciałbym zwrócić uwagę na 2 kontrolki, które są dostępne bezpośrednio „out of the box”: Mapa i Tabela Przestawna. W naszym przykładzie posłużyłem się komponentem Mapy, ponieważ w czytelny sposób pokazuje nam w jaki sposób połączyć 2 modele danych – lokalizację geograficzną miast i wartości akcji na odpowiadających im giełdach.
Tabela Przestawna, choć nie została tu użyta, w praktyce jest najbardziej pożądaną kontrolką w rękach analityka biznesowego. Nie mniej ważna jest zwykła Tabela, ponieważ pozwala na użycie wszystkich typów pól kwerend Qlik Sense – Dimensions, Measures i Detailed, co jest kluczem do eksploracji danych po stronie wielkich repozytoriów (np. Hadoop).
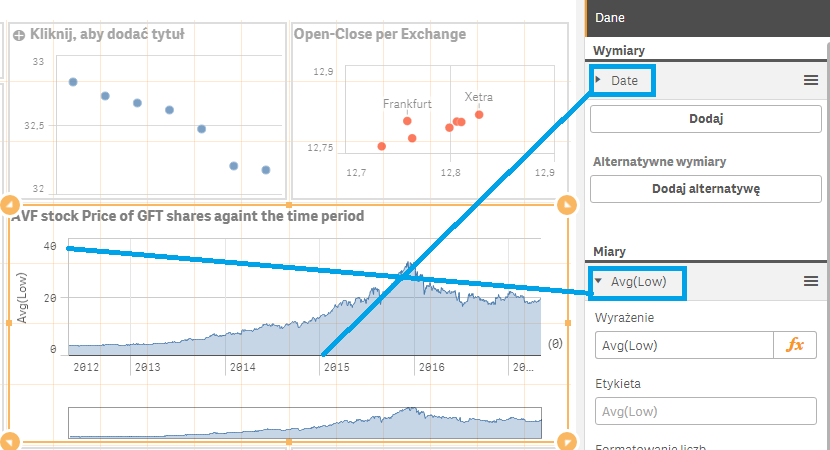
Po umieszczeniu kontrolek na arkuszu, należy każdą z nich skonfigurować, wskazując odpowiednią danę z modelu danych. To brzmi groźnie, ale podobnie jest w Excelu. Jeśli chcemy stworzyć wykres, musimy mieć dane: przy tworzeniu określamy, która kolumna oznacza oś X, a która oś Y. Przygotujmy więc dane.
Dane
Aplikacja Qlik Sense posiada widok zwany „Edytorem ładowania danych”. Jest to miejsce, w którym użytkownik może sam przygotować kwerendę i ją uruchomić.
Możemy posługiwać się składnią Qlik Sense (zalecaną) oraz natywną, specyficzną dla źródła danych. Zazwyczaj deweloperzy i analitycy posługują się zapytaniami, które znają i uruchamiają bezpośrednio przy źródle danych. Jeśli ktoś pracuje z bazą MS SQL, użyje składni dla tej właśnie bazy, a ktoś pracujący z Impalą, skorzysta ze składni Impali (HQL). Często są to skomplikowane kwerendy, które ciężko przełożyć na format Qlik Sense. Na szczęście, tak długo jak jesteśmy w stanie znaleźć sterownik ODBC lub OLE DB, który połączy się z naszym źródłem danych, tak długo możemy pozostać w znanym nam środowisku.
Przykład: Pobranie użytkowników z bazy danych i załadowanie ich do modelu Users
LIB CONNECT TO 'SQLEXPRESS2'; [Users]: LOAD *; SELECT * FROM `dbo.Users`;
Dane nie muszą być pobrane w postaci tabel. Mogą pochodzić bezpośrednio z innych systemów, jako pliki JSON. Tak właśnie jest w naszym przypadku, ponieważ zarówno strona GFT, jak i nasza aplikacja, posługują się właśnie takimi danymi. Dla przykładu, pobranie danych giełdy z Frankfurtu wygląda tak:
[Exchange]: LOAD 'Frankfurt' as Exchange, Date([Date],'DD/MM/YYYY') as Date, Open, High, Low, Close, Null() as Volume FROM [lib://GFT_FRANKFURT] (biff, embedded labels, table is [GFT Technologies SE (Frankfurt)$]);
Możemy to odczytać następująco: Załaduj dane do modelu ‘Exchange’ ze skonfigurowanego konektora ‘GFT_FRANKFURT’. Zwróćmy uwagę na pola ‘DATE’ i ‘LOW’. Są to dokładnie te wartości, których potrzebowaliśmy do stworzenia wykresu powyżej.
Konektor
W poprzednim artykule wskazaliśmy miejsce dla dewelopera w kontekście tworzenia aplikacji Qlik Sense. Jeśli użytkownik pragnąłby uzyskać możliwość budowania kwerend, to deweloper powinien przygotować mu konektor, jako źródło danych do zapytań.
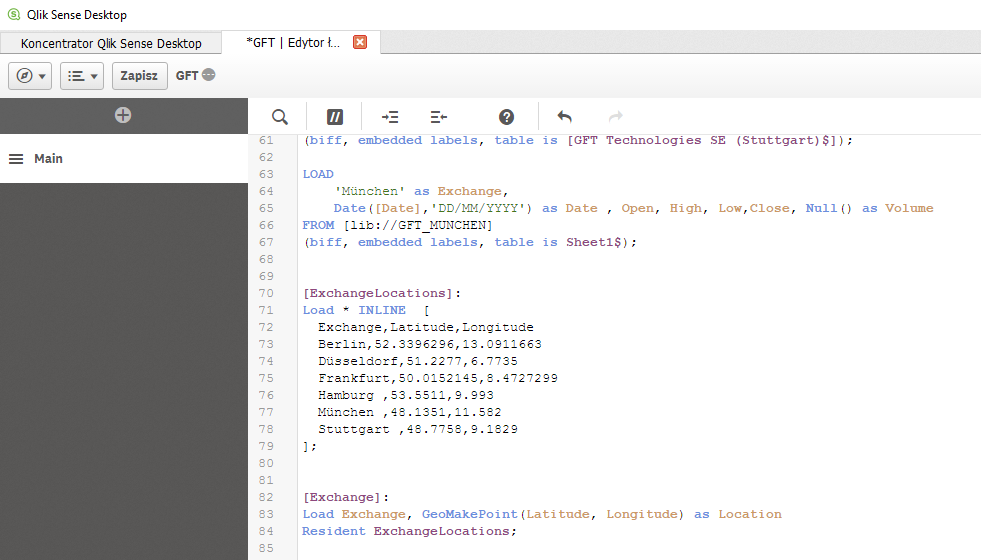
W przykładzie powyżej, [lib://GFT_FRANKFURT] jest takim właśnie źródłem. W praktyce kryje się za tym zapytanie do serwera HTTP.
Może się zdarzyć, że użytkownik, w swej ułańskiej fantazji, postanowi pobrać wszystkie dane z bazy – musimy przygotować się również na taką ewentualność. Rozwiązaniem może być specjalne konto z ograniczonymi uprawnieniami, przygotowane widoki zamiast dostępu tabel lub ustalenie liczby połączeń ODBC do źródła danych.
Ale jak eksplorować BIG DATA?
To, co urzekło mnie w Qlik Sense (Qlik View), to przede wszystkim Direct Discovery. Opiera się na Direct Query, czyli sposobie budowania zapytania, w którym część danych ładowana jest do pamięci, ale część zostanie dociągnięta wtedy, kiedy zajdzie taka konieczność – czyli kiedy użytkownik, klikając po aplikacji, upomni się o nie.
Wyobraźmy sobie, że mamy wykres ze słupkami. Klikamy na słupek z rokiem 2017, a tabela poniżej automatycznie zawęża nam dane, do tego właśnie roku. Tabela zawiera dane zagregowane (tzw. Measures) typu SUM, AVG, MIN, MAX, itp. Takie dane muszą się wyliczyć same i właśnie to ‘wyliczenie’ odbywa się po stronie źródła (np. bazy MS SQL). Qlik Sense stara się operować na danych załadowanych do pamięci (dimensions), jednak nie sposób oczekiwać, aby serwer Qlik Sense, a tym bardziej maszyna użytkownika (w przypadku używania Qlik Sense Desktop), była w stanie załadować wszystkie dane z bazy i trzymać je w gotowości, na wypadek interakcji użytkownika z kontrolką na GUI.
Po stronie źródła danych mogą też istnieć informacje zbyt szczegółowe, aby trzymać je po stronie QS, a jednocześnie nie będące wynikiem funkcji agregującej. Może to być np. komentarz – taką wartość możemy pobrać jako pole typu DETAILED. Informację tę możemy wyświetlić tylko w prostej tabelce, bez możliwości jakiejkolwiek interakcji z innymi kontrolkami na GUI – ale to już zawsze coś.
QVD
Powiedzieliśmy sobie, że jeśli użytkownik chce mieć responsywną aplikację, musi mieć dostęp do danych, a te powinny być obecne w pamięci Qlik Sense, gotowe do użycia. W przypadku interakcji, musimy pogodzić się z tym, że będzie trzeba poczekać, aż dane zostaną przygotowane przez źródło (np. bazę danych), a następnie dostarczone użytkownikowi.
Zazwyczaj takie proste podejście jest nie do zaakceptowania ani po stronie użytkownika, ani specjalistów od infrastruktury (DevOps). Stąd praktycznym rozwiązaniem jest wcześniejsze załadowanie danych z baz do dedykowanych plików QVD, umiejscowionych na serwerze Qlik Sense. Aplikacja pobiera dane z plików QVD, zamiast bezpośrednio odpytywać źródło danych o zawartość. Format QVD jest rozwiązaniem specjalnie opracowanym dla tej technologii, ponieważ przechowuje dane w postaci, w której mogą być bardzo szybko dostarczone do GUI. Operacja jest średnio 10 do 100 razy szybsza od pracy z innymi źródłami danych.
Poza olbrzymim wzrostem wydajności, pliki QVD dają dodatkową korzyść, gdyż mogą być dzielone pomiędzy różnymi aplikacjami Qlik Sense’owymi. Posługując się analogią Excela, można powiedzieć, że wykres w dwóch różnych plikach Excel został zasilony danymi z tego samego źródła danych. Źródło to (QVD) mogło zostać przygotowane przez zupełnie inny zespół, odpowiedzialny za ekstrakcję informacji z oryginalnego repozytorium danych – zweryfikowane, a w razie potrzeby zaktualizowane, uniezależniając użytkownika od zmian w modelach danych po stronie pierwotnego źródła.
W praktyce
Moje doświadczenie z Qlik Sense wyniosłem z pracy przy projekcie dla jednego z największych banków inwestycyjnych na świecie. Stos technologiczny obejmował zarówno rozwiązania Cloudera (Big Data) jak i samego Qlik Sense.
Po dwóch latach pracy muszę przyznać, że technologia przeszła sporą ewolucję i wiele koncepcji nie zawsze przetrwało próbę czasu. Z dużym zaciekawieniem oczekuję wersji Enterprise, opartej o nierelacyjną bazę danych Kasandra, która zastąpi Postgressa. Bez tej zmiany możemy spodziewać się problemów z rozproszoną architekturą proponowaną przez dostawcę QS.
Z kolei martwi mnie wstrzymanie prac nad rozwojem Direct Discovery. Funkcjonalność pozostaje wciąż do dyspozycji klientów, jednak jej utrzymanie nastręcza dostawcy wielu problemów, stąd próby zachęcenia do innych strategii operowania na danych Big Data (np. przez snapshoty).
Innym zagadnieniem, które trzeba mieć na uwadze, to integracja QS z aktualnymi rozwiązaniami w danej firmie. Ogólnie przyjęty sposób promocji aplikacji z użyciem Nolio lub Octopusa będzie wymagał zrewidowania pojęcia samej aplikacji. Rozdzielenie developmentu, konektorów, kontrolek, ekstraktu danych (pliki QVD) i samej aplikacji to tematy, które wymagają szczególnej uwagi.
Uciążliwa może być również kwestia licencyjna i granulacja uprawnień. W wielu firmach otrzymanie dostępu do zasobu w korporacji odbywa się poprzez „change request” i przypisanie użytkownika do odpowiedniej grupy AD. W przypadku QS, integracja z grupami AD jest zbyt uproszczona, a przepisanie licencji musi być robione ręcznie.
Nie mniej jednak, do celów MVP z czystym sumieniem polecam wersję desktop. Jest darmowa i świetnie nadaje się do „wyklikania” widoków i integracji z niemal dowolnym źródłem danych. Jeden wieczór w zupełności wystarczy, aby zobaczyć co dzieje się z akcjami GFT i przyjrzeć się tym samym danym z różnych perspektyw.


