ETL vs. ELT, czyli różne podejścia do zasilenia hurtowni i repozytoriów danych
Czy tworząc hurtownie danych skazani jesteśmy na używanie dodatkowych, często drogich narzędzi do ich zasilenia, takich jak Informatica, SSIS, Pentaho, InfoSphere Data Stage, Ab Initio oraz związanej z nimi dodatkowej infrastruktury? Niekonieczne. W artykule chciałbym zaprezentować alternatywną koncepcję zasilenia hurtowni oraz repozytoriów danych, która może mieć zastosowanie zarówno w tradycyjnych hurtowniach danych, jak i nowych rozwiązaniach starających się sprostać coraz to większym wymaganiom dotyczącym przetwarzania, składowania oraz analizy danych.
Podstawowe pojęcia
Proces ETL w uproszczeniu składa się z 3 kroków:
- Extract – wyładowanie danych ze źródeł i zasilenie przestani tymczasowej – staging area
- Transform – krok, w którym następuje przeprocesowanie danych włącznie z ich uzgadnianiem, czyszczeniem, poprawianiem
- Load – załadowanie danymi hurtowni danych na serwerze docelowym
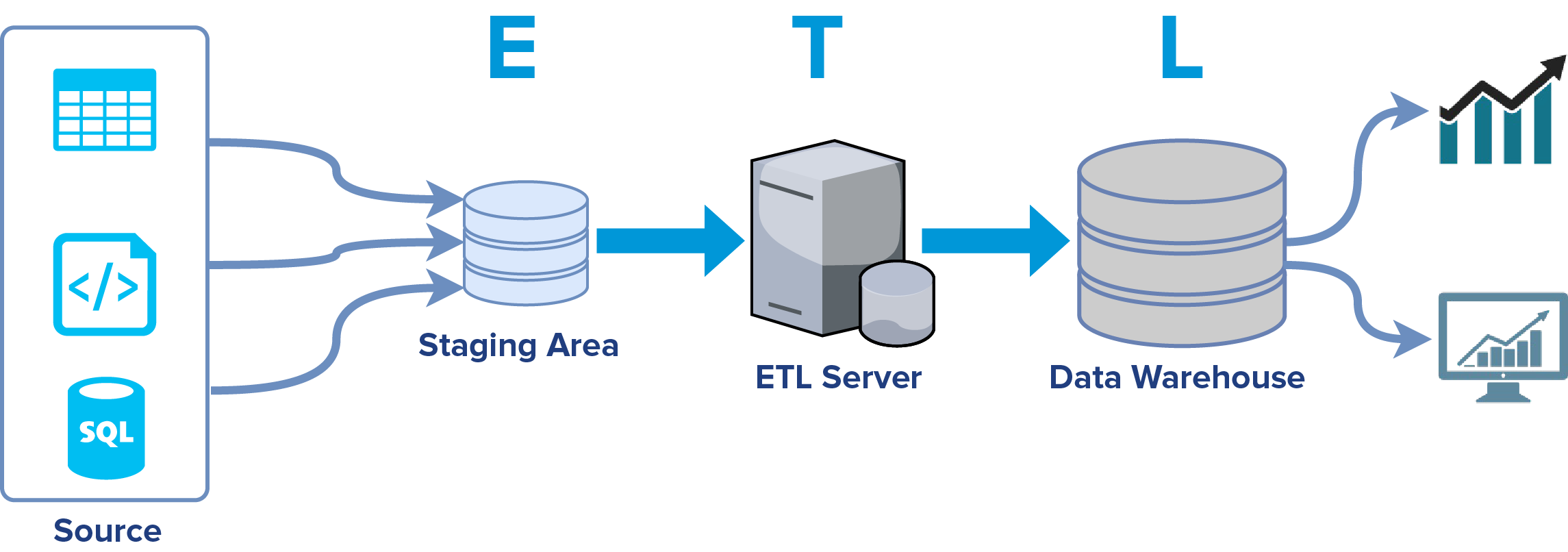
Nie chciałbym skupiać się na wyjaśnieniu całego procesu ETL, ponieważ temat ten jest na tyle obszerny, że powstało mnóstwo publikacji dogłębnie opisujących zagadnienie. Skupmy się na pytaniu: czy proces przepływu danych i zasilenia hurtowni danych musimy zawsze realizować w oparciu o ten model?
W większości przypadków takie podejście wymaga zastosowania dodatkowego narzędzia ETL. Wiąże się to z dodatkowymi kosztami wynikającymi z dodatkowych licencji, serwerów oraz kompetencji, które są niezbędne do projektowania wydajnych przepływów.
Na tym etapie można zadać sobie pytanie, czy można to zrobić inaczej, czasem lepiej, a może i taniej? Odpowiedź nie jest jednoznaczna, ponieważ podejście, które opiszę niekoniecznie należy stosować w każdym przypadku. Nie mniej zdecydowanie należy wziąć je pod uwagę podczas projektowania architektury tradycyjnej hurtowni danych lub rozwiązania tworzonego w oparciu o koncept Big Data.
Czym jest ELT?
Czy jak z samej nazwy wynika, ELT jest jedynie odwróceniem kolejności kroków procesowania – najpierw Load, a później Transform? Nie, a raczej – nie tylko. Podejście to ma swoje daleko idące konsekwencje. W procesie ELT duża część logiki (a czasem i jej całość) związania z ładowaniem i transformacją danych jest przeniesiona na system (serwer) docelowy.
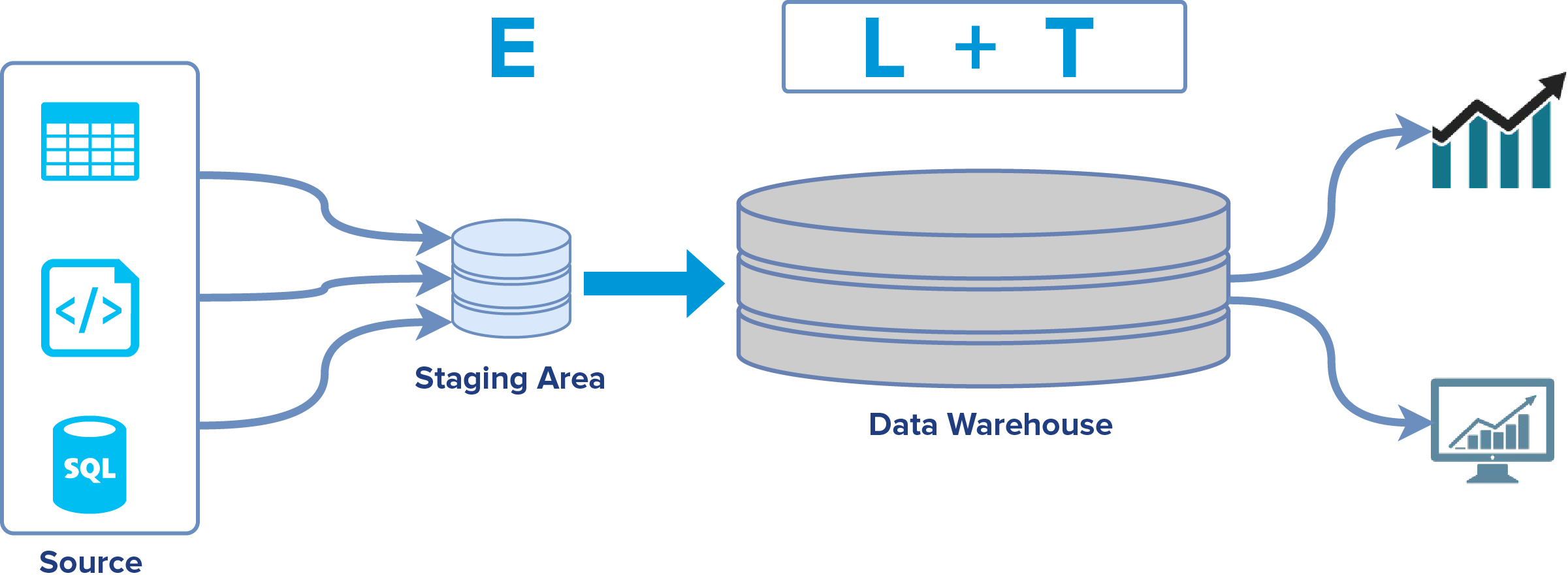
Podsumowaniem zalet i wad obu podejść zajmę się pod koniec artykułu, natomiast już na tym etapie warto wspomnieć, że możemy się obejść bez dodatkowych nakładów na serwer i narzędzie ETL. Konsekwencją tego jest fakt, że po stronie hurtowni danych musimy mieć wydajne maszyny, które udźwigną ciężar wolumenu i transformacji danych.
Krok Extract jest wyładowaniem danych i załadowaniem ich do przestrzeni tymczasowej (staging). Oczywiście możemy do tego zastosować narzędzie ETL, ale o ile nie mamy zbędnych licencji i serwerów, może to być przerost formy nad treścią.
Case Study
Przeanalizujmy model ETL bazując na rozwiązaniu, które realizowaliśmy u jednego z naszych Klientów. W opisywany poniżej projekt weszliśmy w trakcie jego trwania, w związku z czym nie mieliśmy wpływu na architekturę. Dodatkowo, mamy tutaj do czynienia z dwoma wersjami opisanymi jako: Old World (rozwiązanie wygaszane) i New World (czyli nowe, które rozwijamy, a stare migrujemy do nowego).
„Stary świat” (Old World) można opisać kilkoma punktami. Każdy z nich jest kolejnym krokiem w procesie przetwarzania danych:
- Dane dostarczane są w plikach płaskich lub XML
- Dane ładowane są do tabel typu stage
- Dane ładowane są do modelu NF – model, który Klient nazywał modelem znormalizowanym. Gwoli ścisłości, nie był on znormalizowany w rozumieniu 3. postaci normalnej, ale nie ma to większego znaczenia dla omawianego przypadku. Na potrzeby artykułu nazwijmy go modelem NF.
- Model hurtowni danych składający się z tabel faktów oraz wymiarów
- Model przetransformowany do postaci zrozumiałej dla narzędzia BI – QlikView. Można uznać go za swoisty Data Mart.
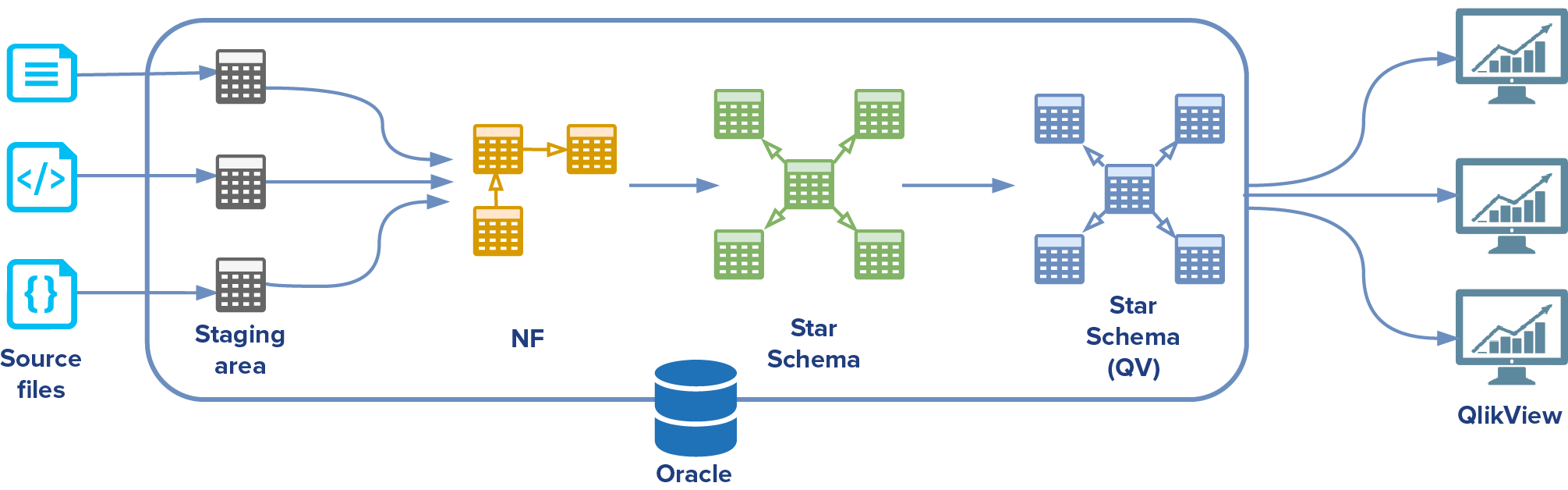
W „starym świecie” dane były ładowane z plików płaskich lub XML do tabel typu stage, przy użyciu procesu napisanego w Javie. Następnie uruchamiany był kod PL/SQL, który transformował dane z tabel stage do modelu NF. Model hurtowni danych oraz model dla QlikView, był tworzony i zasilany danymi w oparciu o widoki zmaterializowane (materialized views), które pobierały dane odpowiednio z modelu NF i hurtowni danych.
„Nowy świat”, różnił się jedynie tym, że dane były ładowane bezpośrednio do modelu NF (Java) z pominięciem tabel pośrednich.
Skąd ta zmiana? Klient nie chciał utrzymywać dodatkowego kodu PL/SQL transformującego dane z przestrzeni tymczasowej do modelu NF.
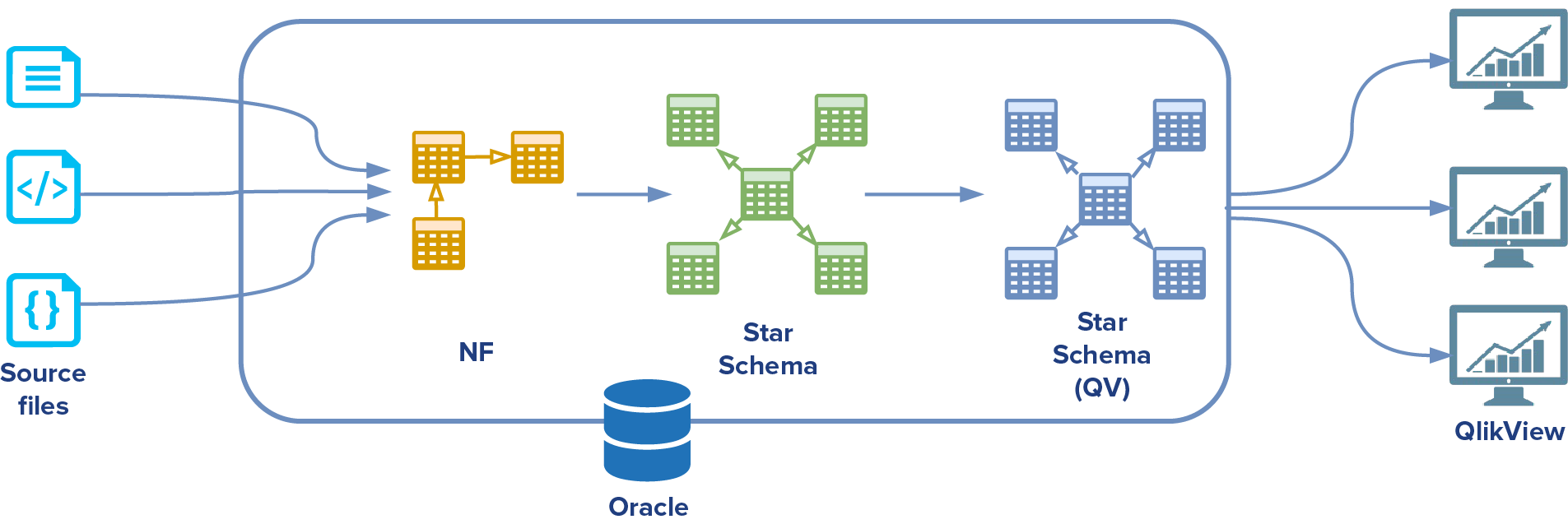
Czy poniższy przypadek jest przykładem realizacji podejścia ELT? Moim zdaniem „stary świat” jest klasyczną implementacją tego konceptu. Jeżeli podejdziemy do sprawy bardzo akademicko, to można powiedzieć, że w „nowym świecie”, w pierwszym procesie oprócz kroku Extract, mamy również Transform (plik -> model NF). Znając jednak specyfikę projektu, krok ten nie był skomplikowaną transformacją, a bardziej przygotowaniem i mapowaniem danych.
Jakie są plusy takiego podejścia? Jak już wspomniałem, nie mamy dodatkowego serwera na potrzeby narzędzia ETL, całe przekształcenie i załadowanie (Load + Transform) jest realizowane na serwerze bazy danych – w tym przypadku był to Oracle.
Oczywiście implementacja modelu hurtowni w oparciu o widoki zmaterializowane jest tylko jedną z możliwości – na pewno nie jedyną i nie zawsze optymalną.
Schema-on-Read vs. Schema-on-Write
Zanim przejdziemy do podsumowania, ważne jest, aby wspomnieć, iż z procesami przepływu danych wiążą się dwa koncepty: Schema-on-Read oraz Schema-on-Write. W skrócie: pojęcia te odnoszą się do momentu, w którym definiujemy jak ma wyglądać nasz docelowy schemat. Nietrudno się domyślić, że tradycyjne podejście do tworzenia hurtowni danych bazuje na koncepcie Schema-on-Write – najpierw definiujemy jak ma wyglądać nasz model, a później go zasilamy. Oczywiście, to jak wygląda nasz schemat jest (a przynajmniej powinno być) przedmiotem analizy procesów, danych i tego, co chcemy osiągnąć.
Koncept Schema-on-Read jest mocno związany z nowymi trendami w procesowaniu oraz składowaniu danych uwzględniając szeroko pojęte Big Data. W tym podejściu nie chcemy determinować jak mają wyglądać dane wyjściowe, zwłaszcza, że mamy technologie, które pozwalają nam składować nierelacyjne dane, w przeróżnych strukturach i formatach. W tym przypadku architektura procesu ELT mogłoby wyglądać następująco:

W takim wariancie, budując np. centralne repozytoria danych dla naszej organizacji (tzw. Data Lake), nie chcemy ograniczać systemów końcowych co do formy pobierania i prezentowania danych. Dane przechowywane tam mogą mieć formę surową (raw data), czyli etap transformacji jest siłą rzeczy na samym końcu procesu.
Z powyższego wynika, że proces ELT możemy rozpatrywać nie tylko w kontekście jednej maszyny, na której wykonuje się ładowanie i transformacja danych, ale również może on znaleźć zastosowanie w koncepcie przechowywania surowych danych w repozytoriach, gdzie decyzję o tym jak te dane będą końcowo wyglądać możemy zostawić ich konsumentom.
“Rozchodzi się jednak o to, żeby te plusy nie przesłoniły wam minusów”
Podsumujmy wady i zalety danego rozwiązania, uwzględniając różne kryteria:
| Kryterium | ETL | ELT |
| Schemat | Podczas tworzenia hurtowni. | ELT nie wyklucza podejścia Schema-on-Write.
Możemy również zdecydować o formie danych podczas ich odczytu z repozytorium danych. |
| Zmiany w modelu hurtowni | Często musimy zmienić przepływ ETL oraz model hurtowni. | Zmiana może ograniczyć się do warstwy hurtowni danych i kroku transformacji, zwłaszcza, jeżeli mamy surowe dane. |
| Infrastruktura | Potrzebne dodatkowe maszyny. | Całość (niekiedy oprócz kroku Extract) może być realizowana na docelowym serwerze, natomiast musi on być wystarczająco wydajny. |
| Kompetencje | Wymagane dodatkowe kompetencje związane z procesami i narzędziami ETL. | W przypadku tradycyjnych hurtowni, często osoby związane z bazami danych mogą realizować krok ładowania oraz transformacji.
W pozostałych przypadkach wymagana jest znajomość technologii, wykorzystywana do przechowywania i procesowania danych. |
| Czas dostępu do danych | W wielu przypadkach proces ETL musi się zakończyć w celu uzyskania dostępu do danych. | Dane szybciej dostępne na docelowej maszynie.
Możemy mieć dostęp do danych surowych przed transformacją. |
| Zastosowanie | Rozwiązanie popularne oraz często stosowane w tradycyjnych hurtowniach danych, gdzie przy dużych wolumenach danych oraz skomplikowanych transformacjach może okazać się bardziej optymalne niż ELT.
Rozwiązanie oparte o ETL może natomiast nie być optymalne kosztowo dla małych rozwiązań. |
Możliwość zastosowania w tradycyjnych hurtowniach danych, ale prawdziwy potencjał można wykorzystać przy przetwarzaniu potężnych zbiorów danych opartych o rozwiązania nastawione na skalowalność oraz dane nieustrukturyzowane. |
Podsumowanie
Co wybrać? Tak naprawdę nie ma jednoznacznej odpowiedzi na to pytanie. Projektując hurtownię danych należy przeanalizować dostępne podejścia i wybrać najlepsze dla danego celu. Co więcej, nasze rozwiązania nie zawsze muszą być podręcznikową realizacją proponowanych metod – czasem mogą stanowić wypadkową wielu różnych podejść.
Nie mniej jednak, jeśli naszym celem jest stworzenie centralnego repozytorium danych, które będzie źródłem dla wielu systemów, warto rozważyć pozostawienie decyzji co do tego jak te dane mają końcowo wyglądać ich konsumentom – zwłaszcza, jeżeli procesujemy też dane nieustrukturyzowane. W takiej sytuacji, ELT jest z całą pewnością interesującą alternatywą.
Źródła
- https://dzone.com/articles/etl-vs-elt-the-difference-is-in-the-how
- https://software.intel.com/sites/default/files/article/402274/etl-big-data-with-hadoop.pdf
- http://richrelevance.com/downloads/RichRelevance%20Tech%20Note%20-%20ETL%20vs%20ELT.pdf
- http://ww1.prweb.com/prfiles/2013/05/05/10703071/Diyotta%20-%20ETL%20vs.%20ELT.pdf
- http://www.marklogic.com/blog/schema-on-read-vs-schema-on-write/
- http://hexanika.com/why-shift-from-etl-to-elt/


