Evaluación y prueba de concepto de tecnologías de procesado en streaming y tiempo real (V): Apache Flink
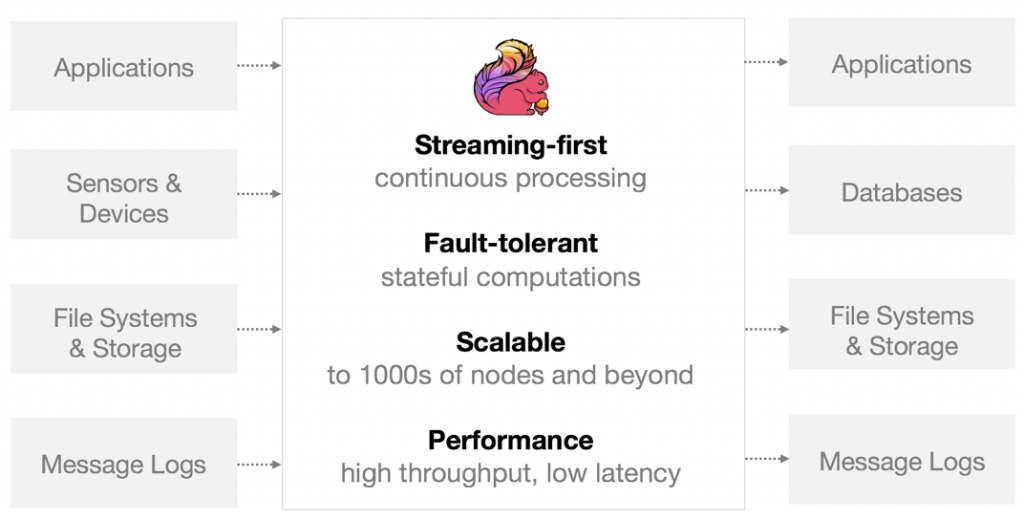
Apache Flink® es un framework de procesamiento en streaming de código abierto para aplicaciones de datos distribuidas, de alto rendimiento y alta disponibilidad. Flink ejecuta programas de flujos de datos de cualquier tipo, de forma paralela o secuencial, y puede funcionar con la mayoría de gestores de clústeres.
Todo empezó como un proyecto de investigación llamado Stratosphere, que se dividió y de esta rama surgió lo que conocemos como Apache Flink. En 2014 fue aceptado como proyecto en Apache Incubator y, pocos meses después, se convirtió en un proyecto top-level de Apache.
¿Qué es y que aporta Flink?
Flink es un framework de código abierto para procesamiento distribuido de datos que:
- Ofrece resultados predecibles, incluso en casos en que los datos llegan desordenados o con retraso.
- Tiene gestión de estado y es tolerante a fallos; se puede recuperar de fallos sin problemas manteniendo la coherencia y asegurando la semántica de envío exactly-once.
- Escala sin problemas, ya que funciona en muchos nodos con muy buenos resultados de throughput y latencia.
- Flink garantiza una semántica exactly-once para cálculos con estado. Con estado significa que las aplicaciones pueden mantener el resultado de una agregación o un resumen de datos que han sido procesados durante un tiempo. Incorpora un mecanismo de checkpoint que garantiza la semántica exactly-once para el estado de la aplicación en caso de fallo.
- Flink soporta procesamiento de streams y gestión por batches con agrupaciones en ventanas de tiempo. La gestión de ventanas de tiempo por evento simplifica la tarea de calcular resultados predecibles sobre streams incluso cuando los eventos llegan desordenados o con retraso.
- En Flink la definición de las ventanas es muy flexible pudiendo ser: basada en un intervalo tiempo, en el número de elementos o sesiones, además de ventanas definidas por el valor de los datos. Las ventanas se pueden personalizar con condiciones de comienzo flexibles para definir patrones de streaming complejos. La gestión de ventanas de Flink permite ajustarse a la forma que tiene el entorno en el que se crean los datos.
- Flink presenta un alto throughput y baja latencia (procesamiento de muchos datos rápidamente).
- Los savepoints de Flink proporcionan un mecanismo para versionar el estado que permite actualizar aplicaciones o reprocesar datos históricos sin perder el estado y con un tiempo offline mínimo.
- Flink está diseñado para funcionar tanto en clústeres con varios miles de nodos, como en un conjunto de nodos independientes; además proporciona soporte para YARN y Mesos.
Apache Flink incluye dos API principales: el API DataStream para streams de datos finitos o infinitos y el API DataSet para conjuntos de datos finitos. Flink también ofrece el API Table, que modela un lenguaje parecido a SQL para procesamiento relacional de streams y de batches que se puede usar fácilmente en las API DataStream y DataSet de Flink. El lenguaje con la abstracción más alta que soporta Flink es SQL, que es semánticamente similar a la API Table y representa programas como expresiones select de SQL.
Evaluación
Al nivel más básico, un programa Flink está compuesto por:
- Origen de datos (source): datos de entrada que Flink procesa
- Transformaciones: el procesamiento en el que Flink modifica los datos entrantes
- Destino de datos (sink): el lugar al que Flink envía los datos después de procesarlos

Source
- Flink posee conectores para varios tipos de fuentes de datos, por ejemplo Kafka, Amazon Kinesis, Apache Nifi, Twitter, etc. En concreto, el consumidor Kafka que hemos probado se integra con el mecanismo de checkpoints de Flink para proporcionar semántica de procesamiento exactly-once. Para conseguirlo, Flink no solo se basa en el registro de offsets del grupo consumidor de Kafka, sino que también chequea y realiza checkpoints de estos offsets internamente.
Transformación
- Procesamiento de mensajes: los programas usando el API DataStream en Flink son programas estándar que implementan transformaciones en streams de datos (p. ej., filtración, actualización de estado, definición de ventanas, agregación…).
Sink
- Posee varios tipos de conectores para enviar datos a diferentes destinos: Cassandra, ElasticSearch, Kafka, HDFS, etc. Por ejemplo, con el conector de Elasticsearch que hemos integrado, activando el mecanismo de checkpoint de Flink, el conector garantiza envíos at-least-once de las peticiones a los clústeres de Elasticsearch.
Conclusión
Apache Flink es una solución potente para el procesamiento de datos en streaming. Está bien documentada y probada, y ofrece muchos ejemplos de diferentes casos de uso. La comunidad es bastante activa y las publicaciones son frecuentes. Se ha convertido en una opción de facto cuando se requiere semántica de entrega exactly-once.
Puedes consultar todos los posts de nuestra serie sobre “real time streaming” aquí



