Cómo usar redes neuronales (LSTM) en la predicción de averías en las máquinas
El Deep learning ha demostrado ser de gran ayuda en diferentes ámbitos, como el reconocimiento de objetos, la clasificación de imágenes, el reconocimiento del lenguaje y diferentes sectores financieros (detección de fraude, fijación de precios, creación de carteras, gestión de riesgos…). Los datos de serie cronológica desempeñan un papel importante en muchos de estos problemas, lo que demuestra la capacidad que tienen las redes neuronales de tratar este tipo de información. En particular, a las redes Long Short Term Memory (LSTM) se les da muy bien aprender de secuencias, lo que las hace muy atractivas en este tipo de contexto.
En el campo del internet de las cosas (IoT), el mantenimiento predictivo es otro ámbito en el que los datos de serie cronológica son muy importantes. Entre otros temas, el mantenimiento predictivo incluye la gestión de averías: predicción, clasificación y diagnóstico. Una rutina de mantenimiento predictivo para un dispositivo o conjunto de dispositivos determinados (ordenadores, generadores eléctricos, máquinas de fabricación, etc.) registra una serie de lecturas de datos a lo largo del tiempo y utiliza estos datos para hallar patrones que sirvan para predecir averías o comportamientos anómalos. Esta predicción se puede utilizar para activar medidas correctivas y así evitar efectos indeseados en el sistema.
Redes LSTM
Las LSTM son un tipo especial de redes recurrentes. La característica principal de las redes recurrentes es que la información puede persistir introduciendo bucles en el diagrama de la red, por lo que, básicamente, pueden «recordar» estados previos y utilizar esta información para decidir cuál será el siguiente. Esta característica las hace muy adecuadas para manejar series cronológicas. Mientras las redes recurrentes estándar pueden modelar dependencias a corto plazo (es decir, relaciones cercanas en la serie cronológica), las LSTM pueden aprender dependencias largas, por lo que se podría decir que tienen una «memoria» a más largo plazo. El funcionamiento exacto de las redes LSTM es bastante complejo y se sale del propósito de este artículo de blog, pero en este enlace se puede leer una descripción más detallada (en inglés): http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
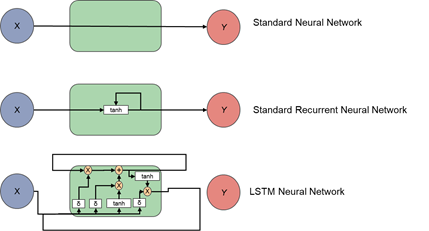
Tipos esquemáticos de redes neuronales. Una salida Yse calcula a partir de una entrada X. En A), Y depende únicamente de X. En B), Y depende de X y del valor anterior de Y. En C), la lógica es más compleja para mejorar el efecto de instancias anteriores de Y (y, por consiguiente, de X).
Objetivo
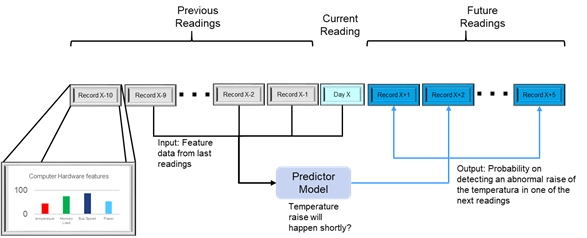
Utilizamos redes LSTM para crear un modelo de mantenimiento predictivo para alertar sobre aumentos de temperatura anómalos en un ordenador.
- En un conjunto de ordenadores se toman lecturas periódicas de las características de rendimiento del hardware (temperatura, uso de la memoria, velocidad de bus, energía consumida…), creando así una serie cronológica de datos para cada ordenador.
- En un momento dado se realiza la predicción para un ordenador basada en los datos incluidos en el segmento de las últimas N entradas de la serie cronológica.
- La predicción ofrecerá una probabilidad acerca de la posibilidad de aumento de la temperatura más alto de lo normal en un periodo del futuro inmediato.
Cómo entrenar una red neuronal
La predicción se obtiene suministrando los datos de entrada a una red neuronal profunda (las N últimas lecturas de características de la serie cronológica). Esta red consta de una primera capa LSTM con 100 unidades, seguida de otra con 50 unidades. También se aplica la técnica de dropoutdespués de cada capa LSTM para controlar el overfitting, o sobreajuste. Por último, una capa final densa con unidad simple y activación sigmoidea proporciona una probabilidad final. Esta configuración sigue la arquitectura diseñada en un problema similar en otra parte (https://github.com/Azure/lstms_for_predictive_maintenance).
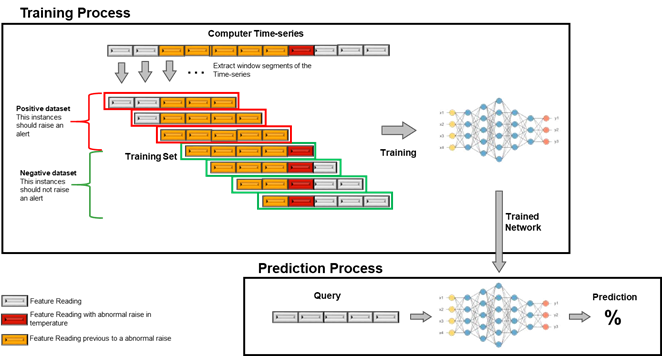
Para obtener una predicción adecuada, esta red se debe entrenar. El entrenamiento es un proceso de aprendizaje iterativo en el que instancias de datos (un segmento de entradas de input) en las que se conoce la salida correcta (vaya o no a haber un fuerte aumento de la temperatura en el futuro cercano) se presentan a la red de una en una, ajustando cada vez los pesos asociados con los valores de entrada en cada capa. El proceso se repite varias veces con diferentes lotes de datos de entrada hasta que los pesos se ajustan lo suficientemente bien como para predecir la etiqueta correcta (o probabilidad) de cualquier muestra de entrada. Para crear las instancias de datos de entrenamiento, se registra una serie cronológica para cada ordenador durante un largo periodo de tiempo. A partir de este grupo de datos se extraen segmentos del tamaño apropiado. Estos segmentos se pueden etiquetar, ya que se puede comprobar si se ha producido un aumento en las entradas posteriores. Este conjunto se utiliza para entrenar los pesos en la red profunda. El conjunto consistirá en instancias positivas (casos en los que la predicción deba ser positiva, es decir, habrá un aumento elevado) y negativas (no se debe predecir ningún aumento).
Implementación
En la implementación realizada en nuestro sistema se han establecido las características siguientes:
- Número de ordenadores: cuatro ordenadores de sobremesa y portátiles utilizados por empleados en las oficinas de GFT
- Equipo de sobremesa típico: Intel i5, 8 GB de RAM y Windows 10
- Lecturas de funciones en ciclos de unos 30 segundos durante un periodo de alrededor de un mes
- Número de lecturas utilizadas para la predicción: 10
- Objetivo de predicción: detectar un aumento de la temperatura anómalo en las próximas cinco lecturas
- Aumento de la temperatura anómalo: diferencia de temperatura entre cinco lecturas superior a 5 °C
- Evaluación: el proceso de entrenamiento se ha realizado en el 66 % de las primeras lecturas de todos los ordenadores. Para probar el rendimiento de la solución se utilizó el 33 % de las lecturas. Para determinar los valores de precisión/recall, se consideró que una respuesta era positiva (habrá un aumento) si el valor devuelto por el modelo era superior a 0,5 (negativo, lo contrario). Para realizar la comparación se diseñó una función de referencia sencilla para predecir la temperatura futura. Con este enfoque, se ajustó una curva sobre las últimas diez lecturas de temperatura para predecir las próximas cinco lecturas. El aumento de estas temperaturas se computa y se utiliza para fines de predicción. Esta referencia se emplea para medir las mejoras obtenidas utilizando el enfoque de machine learning.
- Resultados de las pruebas con los datos:
- Precisión: 0,57
- Recall: 0,47
- Resultados de las pruebas con los datos utilizando el enfoque de referencia:
- Precisión: 0,25
- Recall: 0,45
- Resultados de las pruebas con los datos:
Conclusiones
El uso de las redes neuronales diseñadas introduce una mejora importante en el enfoque de ajuste (fitting). La precisión obtenida (porcentaje de predicciones correctas) aumenta del 25 % a más del 50 %, mientras que la recall (porcentaje de las veces en que se produce un aumento de la temperatura que se predicen correctamente) se mantiene en casi el 50 %. Aunque estos resultados permiten un amplio margen de mejora, esta primera aproximación demuestra que el uso de redes LSTM ayuda a aumentar la calidad de las predicciones. La propia naturaleza del problema puede ser un factor restrictivo, ya que las entradas que se están utilizando pueden ser insuficientes para predecir un aumento de la temperatura y hay otros factores (la interacción del usuario, las actualizaciones de software, etc.) que pueden tener un impacto que estas entradas no registran. En cualquier caso, se espera que, a medida que se disponga de más datos de los ordenadores, mejorará la calidad de las predicciones de los modelos reentrenados, ya que las redes de deep learning se irán expandiendo con grandes cantidades de datos de entrenamiento.
Otras mejoras
Hay algunas técnicas que aún no se han estudiado a fondo en este primer enfoque, pero que pueden ofrecer una versión mejorada del sistema de predicción desarrollado:
- Como decíamos, entrenar las redes neuronales profundas requiere una gran cantidad de datos etiquetados en condiciones heterogéneas para capturar el comportamiento íntegro de un sistema. Dado que esta gran cantidad es inalcanzable muchas veces, se pueden utilizar técnicas de data augmentation, que añaden valor a los datos de base agregando información con una construcción sintética basada en los datos de base. Un ejemplo típico es el del reconocimiento de imágenes, en el que se implementan los «datos aumentados» por medio de alteraciones en las imágenes de entrenamiento, aplicando rotaciones, cambios y volteos. De esta forma, se puede aumentar el tamaño del conjunto de imágenes válidas de entrenamiento. De manera similar, en nuestro caso, la introducción de una señal de ruido puede crear nuevas series cronológicas al tiempo que se mantiene la naturaleza de las originales. De este modo, se puede aumentar el conjunto de entrenamiento y mejorar los resultados.
- En el enfoque implementado se ha utilizado una arquitectura de red fija, pero las modificaciones de esta arquitectura (número de capas, número de nodos en la capa, cuota de dropout, etc.) pueden influir positivamente en el rendimiento. La optimización de los hiperparámetros se puede realizar de forma manual, entrenando diferentes modelos con variaciones de los mismos o, de manera más sistemática, con herramientas proporcionadas por las librerías de frameworks (por ejemplo, Google Cloud ofrece este tipo de funciones).
Con datos como que la precisión obtenida tras el uso de redes neuronales aumenta del 25% a más del 50 % o que la recall se mantiene en casi el 50% nos indican que hay que seguir mejorando, pero que la calidad de las predicciones aumentará, conforme se mejore el diseño de la red y se tengan mas datos de entrenamiento.



