Spanner – Una revolución para los servicios financieros
Cualquier persona familiarizada con los sistemas de bases de datos transaccionales sabe que la gestión de una configuración de bases de datos distribuida puede llegar a suponer un dolor de cabeza. A pesar del progreso de la industria, algunos retos aún quitan el sueño a los sus administradores. La escalabilidad de las bases de datos para acomodar el aumento de la carga, garantizar una alta disponibilidad sin sacrificar la accesibilidad y hacer que los datos sean consistentes en un sistema escalable y altamente disponible no son problemas fáciles de resolver.
Tales retos a menudo se abordan con implementaciones de sharding a medida o alternativas NoSQL.
Para lo primero, piensa en YouTube, Facebook, Twitter y otros. No es necesaria la industria financiera, pero el denominador común para estas compañías son las operaciones globales y probablemente un incremento de tráfico cada vez mayor. Las soluciones a medida tienen reputación de ser muy complejas y sólo unas pocas empresas pueden justificar el coste de su creación. Para lo segundo, NoSQL promete escalar, pero usualmente usa el término eventual consistency que para muchas aplicaciones no es una opción.
Google Cloud Spanner
Spanner destaca en SQL y NoSQL. Es un servicio de bases de datos que aporta lo siguiente a sus usuarios: no necesita instalación (todo funciona en la infraestructura de Google) sharding automático, aplicación del tiempo de inactividad cero, disponibilidad de “cinco nueves” y la interfaz de SQL en la parte superior. Se incluyen tantos nodos como se necesiten. A pesar de ser un sistema distribuido altamente disponible, proporciona grandes garantías de coherencia transaccional. Además, existen importantes ventajas prácticas por su diseño.
En primer lugar, Spanner permite aumentar la cantidad de almacenamiento disponible y la potencia de la CPU sin tiempo de inactividad. La coherencia interna y externa se mantiene siempre, lo que significa que las transacciones se manejan como si se ejecutaran secuencialmente. Puede haber varios dispositivos y diferentes centros de datos involucrados, pero Spanner todavía se comporta como un servidor de DB que se ejecuta en un único módulo. Sin embargo, no es fácil actualizar la CPU o el almacenamiento con una sola máquina sin tiempo de inactividad.
En segundo lugar, las réplicas de Spanner pueden situarse cerca de todos los centros de datos en los que se necesita una solución. Esto permite obtener latencias bajas de la red desde diferentes lugares (continentes), incluso con el módulo único. Con el acceso de Spanner a la infraestructura de red de Google se obtienen latencias muy bajas y una rápida reproducción.
Desgranando los datos
GFT está llevando a cabo actualmente una serie de pruebas de rendimiento para Spanner. Ya hay suficientes ideas para un artículo separado, pero por ahora existe un solo gráfico de rendimiento mostrando el upscaling de Spanner bajo carga pesada. Durante la prueba, hubo ~ 6000 transacciones de escritura / s. El cambio es de 3 a 7 nodos @ 15.29.19 que se representa con la línea gris. NYK / TKY / LDN son tres fuentes distintas de carga simulando un escenario de acceso global.
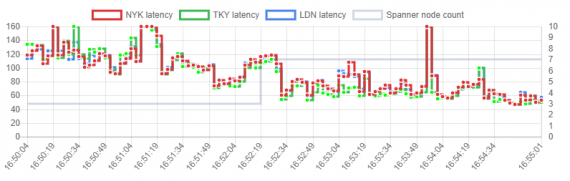
Spanner necesitó alrededor de medio minuto para cortar latencias de consulta de> 100ms a <60ms. Lo que no es visible en el gráfico es la consistencia transaccional que se mantiene en todos los nodos. Otro punto importante aquí es que todo el proceso de reescalado se reduce a poner un número en el campo de configuración:
Añadir imagen campo de configuración
La configuración de Google Console vincula el rendimiento y la capacidad, lo que significa que aumentar el número de nodos funciona tanto para resolver el rendimiento como para los problemas out-of-space.
¿Qué pasa con los desarrolladores?
¿Qué esperar si eres desarrollador? Bueno, como ya se podría adivinar, los problemas que Spanner resuelve son de Ops (operaciones) en lugar de Devs (desarrollo). La buena noticia es que Spanner soporta consultas SQL y proporciona API para algunos lenguajes populares, Java (JDBC), Python, Go y Node.js incluidos. Sólo tuve la oportunidad de probar el de Java y es realmente accesible.
A pesar de la falta de DML, la compatibilidad de SQL es grande, aunque hay algunos problemas que uno debe tener en cuenta. Por favor, consulta la siguiente sección.
¡Lo tengo!
En 2012, Joel Spoolsky escribió: “Todas las abstracciones no triviales, en cierto grado, tienen fugas”. Spanner es claramente no trivial. La mayoría de sus complejidades no son visibles para los usuarios, pero aun así, sólo hay que tener en cuenta el hecho de que hay un montón de cosas que suceden detrás de las cámaras y que pueden influir en el rendimiento e imponer algunas limitaciones en el diseño del modelo de datos.
Por ejemplo, la capacidad de Spanner para escalar depende del diseño del esquema adecuado. Uno de los anti-patrones son las monotonic keys, algo a lo que la mayoría de los desarrolladores están muy acostumbrados. El algoritmo de escalado aplica el sharding automáticamente, lo que significa que no existe un control total sobre cómo y cuándo Spanner decide reorganizar sus datos. De alguna manera, esto se parece al compilador just-in-time de Java, que es capaz de cambiar las características de rendimiento mientras un programa se está ejecutando. Esto es una gran característica, pero también significa que algunas métricas de rendimiento pueden cambiar algo inesperadamente.
También hay algunas limitaciones, como el optimizador simple y la falta de DML. El problema del optimizador es especialmente molesto ya que conduce a que la indicación se use de forma extensiva para el índice. Pero estos problemas se deben posiblemente a la corta edad de Spanner y se espera que se solucionen pronto.
¿Qué significa esto para nosotros?
Spanner es realmente un gran avance para GFT. Básicamente significa que somos capaces de proporcionar a nuestros clientes soluciones rentables que hasta ahora eran demasiado caras o complejas para implementar. En lugar de ser un nuevo marco de moda para el almacenamiento de datos, es un intento de resolver viejos retos con los que las instituciones financieras están familiarizadas.
¿Te interesa saber más sobre este tema? Apúntate entonces al Webinar que organizamos GFT y Google conjuntamente el próximo 8 de febrero, donde expertos de ambas compañías darán a conocer cómo esta nueva herramienta se hará con el control del mercado de soluciones en la nube.



