Aplicaciones Streaming y Deep Learning: claves del Spark Summit 2017
A finales del pasado mes de octubre se celebraba en Dublín una nueva edición del Spark Summit, poniendo de manifiesto que sigue gozando de mucho apoyo de la comunidad open source y que sigue extendiéndose su uso al ámbito Enterprise. Esta solución de código abierto permite el procesamiento distribuido de grandes volúmenes de datos, proporcionando un API de alto nivel que facilita a los desarrolladores enfocarse en la lógica de negocio.
Apache Spark es una solución de código abierto para Cluster Computing, que se encuentra en la vanguardia del procesamiento distribuido en el ecosistema de Hadoop. Este cuenta con muchas ventajas en comparación con el paradigma Map Reduce anterior. Como resultado, existe una gran comunidad que colabora con esta iniciativa y utiliza esta tecnología en diferentes áreas: sector bancario, energía, industria publicitaria, etc.
El evento Spark Summit llegó a Dublín este año para compartir todo este conocimiento sobre lecciones aprendidas, casos de uso real, nuevas características y áreas de investigación actuales. Las principales tendencias actuales en la comunidad Spark son las aplicaciones de procesamiento en streaming y las aplicaciones de Spark en Machine Learning, principalmente enfocado a las redes neuronales profundas o Deep Learning.
Este año el congreso se dividió en 9 tracks (Desarrollador, Streaming, Data Science, Técnico en Deep Dives e Ingeniería de datos, etc.), si estás interesado, puedes acceder a todos los vídeos.
Matei Zaharia, creador de Spark, fue el encargado de inaugurar el evento, en el que explicó las principales actualizaciones hechas por la comunidad en Spark 2.x en dos áreas principales: procesamiento en Streaming con Structured Streaming y Deep Learning con bibliotecas de alto nivel como Deep Learning Pipelines y TensorFlowOnSpark. En ambas áreas, ha sido un gran paso adelante ofrecer las mismas APIs de alto nivel utilizadas en el resto del ecosistema Spark (por ejemplo, DataFrames y ML Pipelines), mejorando tanto la escalabilidad como la facilidad de uso en aplicaciones de streaming o de Machine Learning.

Como ejemplo del uso de Spark a gran escala, Facebook y Neustar compartieron sus experiencias en la construcción de flujos de procesado para grandes volúmenes de datos. Por un lado, Facebook mostró sus flujos de Instagram para procesar volúmenes diarios o alrededor de 300 TB de entrada y 90 TB de datos de referencia. Se debatieron algunos consejos y trucos aprendidos, como migrar de RDD a Dataset para mejorar la eficiencia de la memoria o dividir los flujos de larga duración para ajustar mejor los datos datos de joins. Neustar presentó su solución aplicada en el sector publicitario para procesar más de 10 mil millones de eventos por día en trabajos ETL en batch. Ese gran volumen ha implicado tener que tunear los trabajos de formas específicas para lograr una paralelización masiva mientras se mantiene el uso de la memoria lo más bajo posible. Algunos ejemplos del ajuste realizado fueron: optimización del uso de la memoria con Ganglia, optimización del uso de particiones para las diferentes fases de los workflows, modificación de la configuración predeterminada de Spark para trabajos de gran volumen, etc.
En cuanto a la siguiente inundación de datos que veremos con el Internet de las cosas, el CERN explicó su solución en el acelerador LHC para recopilar y registrar los datos de todos los dispositivos y sensores que están monitorizando esta enorme máquina. El rendimiento del LHC ha alcanzado nuevos niveles, y como resultado, la cantidad de datos producidos por la infraestructura subyacente y los sistemas de observación se ha incrementado en un orden de magnitud, colocando una carga sin precedentes en el servicio de registro de datos actual. En esta charla, el ingeniero de CERN explicó las motivaciones detrás de la evolución del Servicio de Registro del Acelerador del CERN hacia una nueva arquitectura basada en Hadoop y Apache Spark.

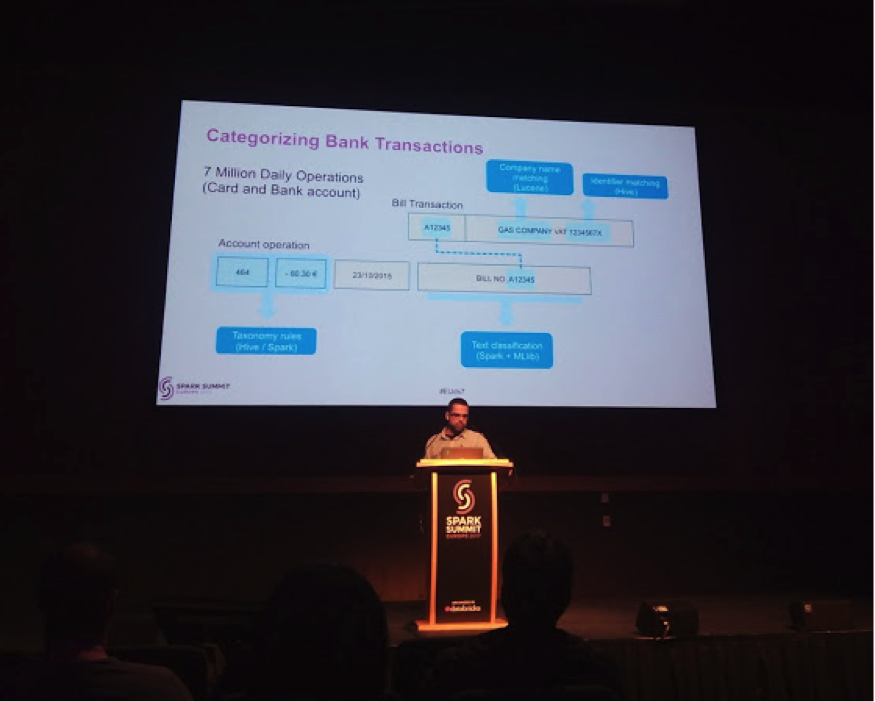
Desde la perspectiva bancaria, se presentaron varias soluciones usando Spark en el sector minorista y mercado de capitales. Desde la perspectiva de la banca minorista, BBVA presentó su solución para la categorización de transacciones, utilizando la biblioteca MLLib de Machine Learning. Esta aplicación se encuentra actualmente en producción categorizando las transacciones realizadas para más de 5 millones de clientes diariamente. El jefe del equipo de Ciencia de Datos de BBVA presentó el reto de lograr esto, incluido el problema de clasificar 700 mil transferencias diarias realizadas por personas, que adivinan la categoría en función de campos de texto libre.
Desde los mercados de capitales, Barclays presentó una solución de código abierto llamada Spline para el linaje de datos. Esta herramienta captura y almacena información de linaje de los planes de ejecución internos de Spark y la visualiza de una manera fácil de usar. El seguimiento del linaje de datos es uno de los problemas importantes al que se enfrentan las instituciones financieras al usar herramientas modernas de Big Data, y existen muchas reglamentaciones como la IFRS 9 que requieren que este linaje se proporcione para cualquier información procesada o generada.

Como conclusión, solo destacar que la comunidad Spark está poniendo mucho esfuerzo en evolucionar para abordar los retos de su uso en soluciones de negocio. Como resultado, muchas empresas y sectores están usando Spark diariamente para mejorar sus procesos y desarrollar sus negocios a fin de comprender mejor los datos y mejorar su toma de decisiones.



