Evaluación y prueba de concepto de tecnologías de procesado en streaming y tiempo real
En pleno apogeo del Big Data, los enormes volúmenes de datos cada vez mayores y las necesidades de obtención de resultados en tiempo real han puesto en primera línea a las tecnologías streaming. Este nuevo paradigma abre un mundo de posibilidades en la gestión y el procesamiento de datos. En este artículo explicamos el potencial del paradigma de streaming y las herramientas existentes actualmente en el sector que hemos evaluado de forma teórica. En el próximo artículo hablaremos en detalle de la prueba de concepto práctica realizada con las tecnologías más interesantes.
Motivación
Las tecnologías de streaming están causando furor últimamente. En el amanecer de la revolución del big data, los frameworks de procesamiento como MapReduce y, más tarde, Spark, funcionaban muy bien con los flujos de trabajo por lotes (batch). Sin embargo, no podían proporcionar información en baja latencia ni operaciones en tiempo real. Los volúmenes de datos disponibles, que crecían continuamente, y la necesidad de obtener información sobre ellos lo más rápido posible requerían una nueva generación de herramientas que pudieran solucionar este problema.
Hubo muchas herramientas que acudieron al rescate. Algunas de ellas están basadas en una solución que ya existía (como Spark Streaming, Kafka Streams o Akka Streams) y otras nuevas utilizan un enfoque de streaming de datos más fresco y sin concesiones (Flink o Apex). Hay incluso una capa de abstracción que puede usar diferentes runners (Beam). Dado que existe un alto grado de solapamiento de características entre ellas, hemos creído muy conveniente obtener una comprensión más amplia y una imagen clara del panorama actual.
Teoría básica del streaming
Antes de presentar las tecnologías evaluadas y el resultado de nuestra investigación, vamos a explorar algunos conceptos básicos del paradigma del streaming.
- Garantías de entrega: en una transmisión existe un origen/productor y un consumidor de datos, y los datos viajan entre los dos puntos a través de un flujo/canal (la terminología varía). En cualquier caso, pueden producirse problemas en cualquier punto de la transmisión. Veamos los pros y los contras de las diferentes estrategias que hay:
- At most once (como mucho una vez) significa que se envía el mensaje, pero al emisor no le importa si se recibe o se pierde. Si la pérdida de datos no es un problema ―que podría ser el caso, por ejemplo, con la monitorización de telemetría―, este modelo no implica más carga de trabajo para garantizar la entrega del mensaje, como requerir el acuse de recibo de los consumidores. Por lo tanto, es el comportamiento más sencillo y eficiente.
- At least once (al menos una vez) significa que la retransmisión de un mensaje tiene lugar hasta que se recibe un acuse. Dado que un acuse retrasado del receptor podría producirse cuando el emisor envía el mensaje, este podría recibirse una o más veces. Este es el modelo más práctico cuando la pérdida del mensaje no es aceptable (p. ej., en operaciones bancarias), pero puede haber duplicación.
- Exactly once (exactamente una vez) garantiza que un mensaje se recibe una sola vez y que nunca se pierde ni se repite. El sistema debe implementar los mecanismos oportunos para garantizar que un mensaje se reciba y se procese una sola vez. Este es el escenario ideal desde una perspectiva de usuario, dado que el manejo del estado del sistema ya está siendo gestionado por la herramienta subyacente. Es imposible de implementar en casos generales, pero se puede aplicar con éxito en casos específicos (al menos con un porcentaje alto de fiabilidad).
- Ventanas: el proceso de transmisión sirve para un tipo de datos que no es ni grande ni pequeño: es infinito. Sin embargo, los datos llegan a un cierto ritmo. Es imposible obtener una visión total sobre unos datos infinitos, pero podemos ver fragmentos: los eventos de las últimas dos horas o los últimos 1000 eventos. Este fragmento es una ventana. Aunque suene sencillo, existen varias clasificaciones y diferentes problemas derivados de ellas:
- Ventana basada en el tiempo
- Hora del evento: una marca de tiempo lógica que depende de los datos y que está incrustada en el evento
- Hora de incorporación: una marca de tiempo que se asigna cuando el evento entra en el sistema
- Hora de procesamiento: el tiempo real cuando se procesa el evento
- Ventana basada en el tiempo
La hora del evento es la más útil… y problemática. ¿Qué pasa si los eventos llegan desordenados o más tarde de lo esperado? Una solución heurística es utilizar marcas de agua (watermarks), es decir, especificar un tiempo en el que permitimos que los datos lleguen tarde, manteniendo la ventana en la memoria hasta ese punto.
- Tipo de ventana
- Fija: el tiempo se divide en segmentos del mismo tamaño que no se superponen. Un evento pertenece a una ventana.
- Deslizante: ventanas de tamaño fijo separadas por un intervalo habitualmente inferior al tamaño de la ventana. Un evento pertenece a varias ventanas.
- Sesión: ventanas no definidas por el tiempo, sino por los datos. Un evento pertenece a una sesión. Suelen terminar con un intervalo de inactividad superior a un timeout definido.
- Activación
¿Cuándo se debe activar la computación? ¿Al final de la ventana? ¿Al final de la marca de agua? ¿Debería recomputarse varias veces mientras la marca de agua obtiene nuevos datos/progresa en el tiempo? ¿Debería depender de ciertos valores en los datos?
- Autoescalado, también conocido como escalado elástico o dinámico, asignación (de recursos) dinámica o rebalanceo dinámico del trabajo. El autoescalado no es lo mismo que el balanceo de carga, ya que permite aumentar (o disminuir) automáticamente la potencia de procesamiento cuando se dan determinadas condiciones.
- Backpressure es un medio de control del flujo, una manera en que los consumidores de datos notifican a un productor su disponibilidad actual, ralentizando efectivamente al productor para igualar las velocidades de consumo. Esto impide que los datos desborden al consumidor o búferes intermedios, en caso de haberlos.
- Modelo de programación
- El enfoque compositivo proporciona bloques constructivos básicos, como fuentes u operadores, que deben estar unidos para crear la topología esperada. Habitualmente se pueden definir nuevos componentes implementando algún tipo de interfaz.
- Las API declarativas se definen como funciones de orden superior. Nos permiten escribir código funcional con tipos abstractos y otras atractivas y útiles propiedades, y el propio sistema crea y optimiza la topología. Por lo tanto, las API declarativas proporcionan operaciones más avanzadas listas para usar, como funciones de ventana o gestión del estado. Muy pronto veremos algunas muestras de código.
Panorama de herramientas de streaming
Como mencionábamos antes, existen muchas herramientas de streaming. Hemos realizado una evaluación teórica de las siguientes:
- Apache Spark Streaming
- Kafka Streams
- Akka Streams
- Apache Flink
- Apache Beam
- Apache Apex
- Apache Ignite
- Apache Gearpump
- Apache Storm
- Apache Samza

Evaluación
La tabla siguiente muestra lo que cada una de estas herramientas ofrece.
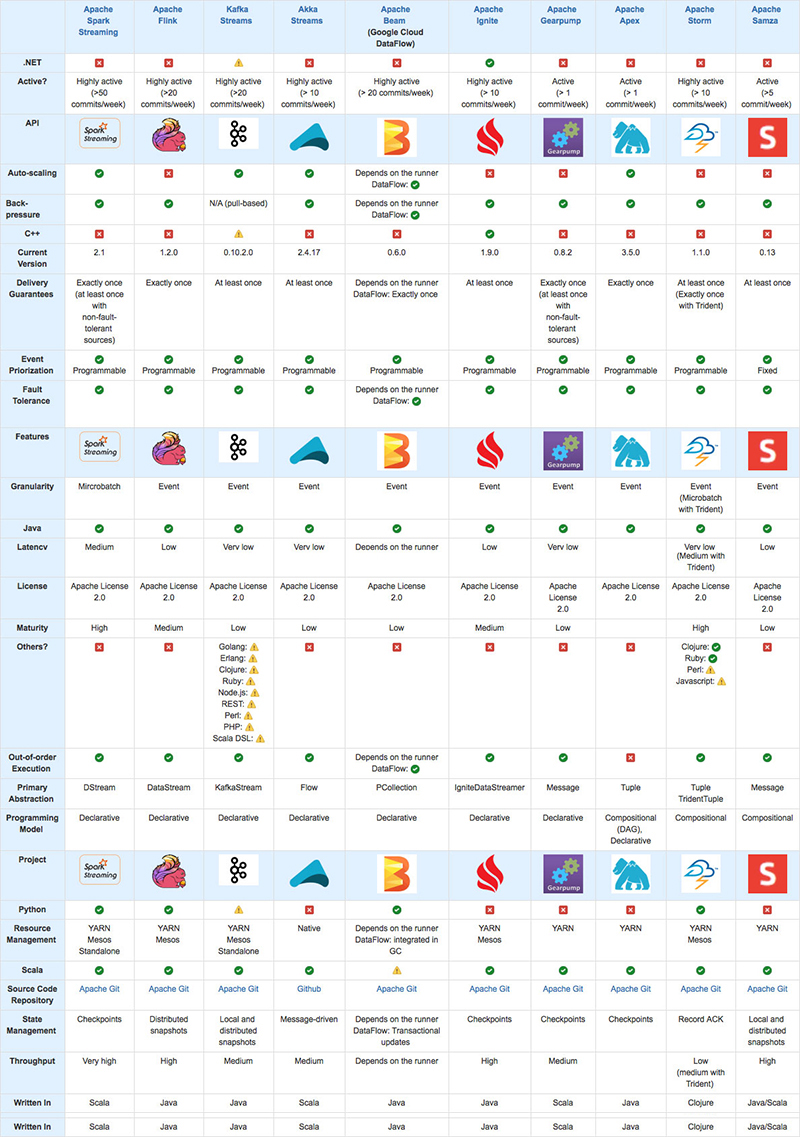
Herramientas no incluidas
Aunque es difícil que quepan las tecnologías evaluadas en una sola página, aún hay muchas más herramientas que hemos tenido que dejar fuera de la evaluación por varios motivos: falta de popularidad, operadores de nicho, acoplamiento con otros sistemas, vendor-locking o inviabilidad del testing. Esta es una lista de algunas de ellas:
- Comerciales:
- Código fuente abierto:
Conclusiones
Algunas de nuestras conclusiones principales son:
- Si ya estás usando el ecosistema Spark, continúa con Apache Spark Streaming.
- Si empiezas de cero, vale la pena que empieces con Apache Beam para que puedas seleccionar un runner más tarde en función de tus requisitos de latencia.
- Si ya tienes Kafka en tu arquitectura y no necesitas un ETL sencillo para tu transmisión, Kafka Streams es una buena opción.
- Akka Streams y Gearpump son más adecuadas para crear microservicios generales sobre streaming de datos.
- Si ya estás utilizando un clúster YARN, podrías beneficiarte de herramientas que ya puedan funcionar con él.
- Las primeras herramientas de streaming, como Flink, Gearpump o Apex, a menudo ofrecen una API más clara y se especializan en proporcionar más características de solo streaming y un mejor rendimiento. Echa un vistazo a tu caso de uso para ver si esto es necesario.
Más información
Además de la documentación específica sobre streaming que encontrarás en las páginas de herramientas en sí, Tyler Akidau escribió un par de artículos excelentes, ya clásicos, sobre todo lo relacionado con el streaming: Streaming 101 y Streaming 102. Aunque tienen ya dos años, ofrecen una introducción clara y detallada al mundo del streaming.
En el próximo artículo volveremos con la prueba de concepto implementada en una selección de las tecnologías más destacadas que hemos presentado aquí.
¡No te lo pierdas!
La evaluación de tecnologías de streaming y tiempo real se ha realizado con la colaboración especial de nuestros compañeros en GFT: Sergio Gómez en la parte teórica, e Ignacio Asín, Roberto López, Sara Reig, Ignacio Estrada, Jordi Rodríguez en la parte práctica. ¡Gracias a todos!



