Cómo agregar logs distribuidos con Elasticsearch
El uso de infraestructura distribuida para satisfacer los altos requerimientos de cómputo y almacenamiento de datos está cada vez más extendido en prácticamente cualquier sector debido al incesante volumen de generación de datos. Además, esta infraestructura está muchas veces compartida por distintos usuarios y aplicaciones con muy variados patrones de uso; desde aplicaciones de procesamiento masivo y programado hasta usuarios haciendo un uso interactivo y a medida. En este escenario tan heterogéneo, es necesario ofrecer mecanismos tanto para que los responsables de las aplicaciones monitoricen y evalúen el correcto funcionamiento de ellas, como para que los administradores de la infraestructura puedan comprender el uso que las aplicaciones están haciendo de la misma. Siendo los logs una de las herramientas de monitorización básicas, disponer de un servicio que recopile y agregue estos logs para ofrecerlos a sus usuarios de una manera integrada facilita dicha monitorización. El reto aquí es poder hacer esta integración de una manera lógica y completamente transparente de unos logs generados en un entorno distribuido.
Una vista centralizada y agregada de todos los logs generados por cada una de las aplicaciones de una infraestructura compartida y distribuida facilita a los usuarios la monitorización de sus aplicaciones. De lo contrario, la explotación de la información disponible en estos logs requeriría que los usuarios manualmente recolectaran y procesaran estos logs diseminados a lo largo de la infraestructura. La recolección y agregación automática de estos logs habilita tanto su almacenamiento a modo de histórico como su posterior acceso, análisis y explotación visual, considerando además su dimensión temporal.
Como prueba de concepto, el centro de competencia de Data de GFT ha diseñado e implementado la agregación de logs como servicio transversal para todos los usuarios en un Data Lake, como ejemplo de infraestructura distribuida y compartida. En esta implementación inicial, el servicio de agregación de logs permite supervisar los siguientes casos:
- Servicios propios del Data Lake: la agregación de los logs generados por todos los servicios propios de la plataforma Hadoop (NameNodes, DataNodes, ResourceManagers, etc.)
- Aplicaciones YARN: la agregación de los logs generados a nivel de aplicación YARN, es decir, entrelazando los logs de todos los contenedores que conforman una aplicación YARN.
- Aplicaciones: la agregación a nivel de aplicación de usuario, es decir, permitiendo la agregación de distintas ejecuciones de la misma aplicación que se ha ejecutado múltiples veces, resultando en múltiples instancias de aplicación YARN.
- Métricas personalizadas: permitir que las aplicaciones publiquen sus propias métricas a medida y ofrecer mecanismos para que el usuario pueda explotar todas estas métricas aumenta las capacidades de supervisión de las aplicaciones, así como poder observar y predecir su rendimiento, e incluso poder medir la calidad del servicio que sus aplicaciones prestan.
Arquitectura
La arquitectura para esta solución está basada en el conocido conjunto de tecnologías que ofrece Elastic:
- Elasticsearch para el almacenamiento y la indexación de los logs.
- Logstash para el encaminamiento, procesamiento y enriquecimiento de los logs.
- Kibana para la visualización.
Además, también se han utilizado Metricbeat, para la captura de métricas a nivel de sistema operativo, y Filebeat, para el consumo de los ficheros de log y su envío hacia Logstash.
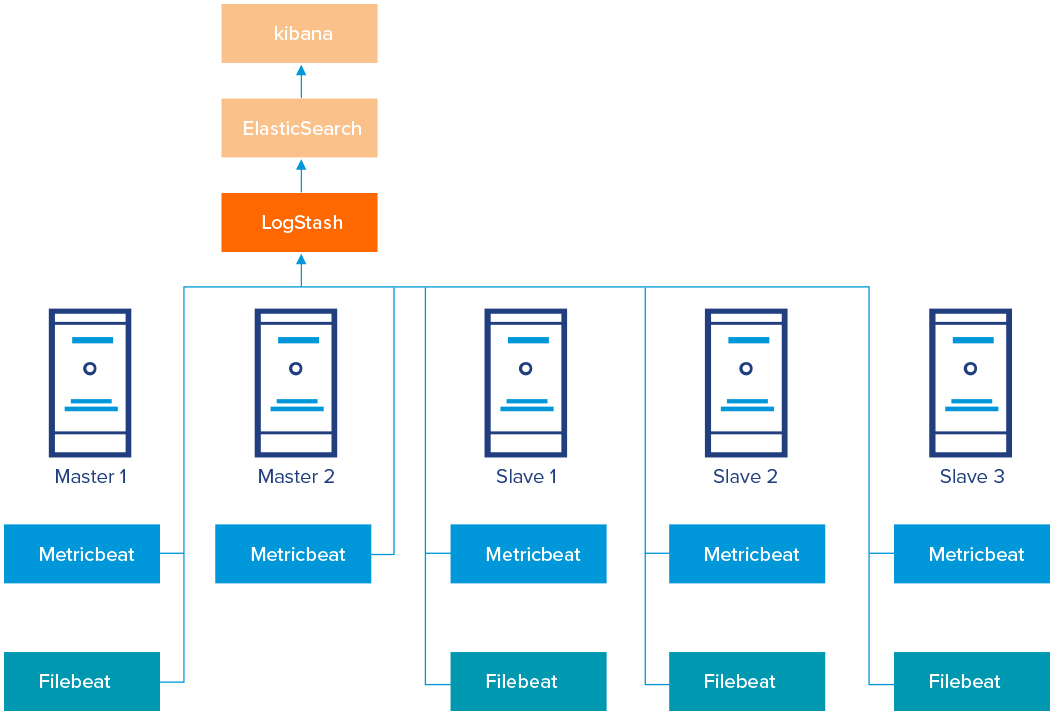
El gráfico anterior muestra los detalles de la arquitectura, que consiste en:
- Todos los nodos del clúster:
- Metricbeat para obtener parámetros del sistema: CPU, memoria, uso del sistema de archivos, etc.
- Nodo master1
- Filebeat para supervisar los logs de los siguientes servicios: NameNode, SecundaryNameNode, ResourceManager, Hive Metastore, Oozie, etc.
- Nodos slave[1-3]
- Filebeat para supervisar:
- Los logs de los siguientes servicios: DataNode, NodeManager.
- Los logs de los contenedores YARN (es decir, supervisión de los logs generados en /yarn/container-logs/<yarn_app_id>/<yarn_container_id>/*). Nótese aquí que todas las aplicaciones de usuario se ejecutarán como aplicaciones YARN en forma de contenedores distribuidos. Por lo tanto, todos los logs que dichas aplicaciones produzcan serán almacenados y capturados a nivel contenedor.
- Filebeat para supervisar:
Todas las instancias de Metricbeat y Filebeat envían datos al servidor de Logstash en el nodo master2. Además, Logstash permite realizar algunas transformaciones en los registros de log antes de ser indexados en Elasticsearch, también desplegado en el nodo master2.
Esta arquitectura permite implementar distintos mecanismos para enriquecer las trazas de log que las distintas aplicaciones generan con nuevos metadatos en distintos casos de uso. En su posterior visualización, estos metadatos permitirán la explotación de las trazas de log en distintos paneles de control.
Casos de uso
Agregación de logs de YARN
El propósito de la agregación de logs de YARN es enlazar todos los logs de una misma aplicación YARN. Para ello, es necesario identificar tanto la aplicación como el contenedor YARN al que corresponde cada uno de los registros de log. Este paso de enriquecimiento se puede realizar en Logstash definiendo un filtro con una expresión regular en el campo source (que corresponde a la ruta de archivo de la que se obtuvo el seguimiento del registro y que es uno de los metadatos que automáticamente incorpora Filebeat al consumir las trazas de log de sus ficheros originales).
Como se puede ver en el fragmento de código anterior, se aplica una expresión regular en la ruta del archivo fuente y, en caso de coincidencia, tanto el identificador de la aplicación (applicationId) como el identificador del contenedor (containerId) se añaden automáticamente como nuevos metadatos al registro de log.
Agregación lógica de logs
La agregación lógica de logs, a diferencia de la anterior, enlaza logs procedentes de distintas ejecuciones de una misma aplicación, es decir, procedentes de múltiples aplicaciones YARN. En este caso, un identificador único por aplicación debe incluirse en los logs desde la propia aplicación de manera que Logstash pueda capturarlo y usarlo para enriquecer nuevamente el registro de log.
Una posible solución es que los usuarios sigan una convención a la hora de generar las trazas de log de sus aplicaciones. La convención puede ser algo tan sencillo como incluir un identificador único de la aplicación en las trazas de log con un formato específico. Téngase en cuenta que esta convención se puede forzar por configuración mediante log4j. Otra posible solución para este problema podría ser la publicación de los logs en colas exclusivas por aplicación de usuario. En ese caso, Logstash podría recolectar todos los logs a partir de las colas, en vez de supervisando los ficheros donde se generan, agregando todos los logs procedentes de una misma cola, es decir, de una misma aplicación de usuario.
A modo de ilustración y por su simplicidad, en esta implementación hemos optado por la convención de incluir el identificador único de aplicación en cada una de las trazas de log generadas. Véase a continuación un ejemplo de traza de log generada por una aplicación cualquiera a modo de ejemplo. Obsérvese cómo la traza incluye el identificador único de aplicación:
| 17/03/01 07:06:26 INFO com.gftlabs.practice.data.SampleApplication: LOGICAL_APP_ID[ID0001] this is just a sample log trace |
Asumiendo esta convención en las trazas de log de todas las aplicaciones, este identificador se puede capturar nuevamente con una expresión regular en Logstash mediante un nuevo filtro que, en caso de coincidencia, añade un nuevo metadato en el registro de log.
Así, todas las trazas de log que sigan la convención serán enriquecidas por Logstash agregando el logicalAppId con su valor correspondiente como un metadato más.
Métricas personalizadas
El siguiente fragmento de código muestra una aplicación Spark que, a modo de ejemplo, implementa el problema del recuento de palabras y publica algunas métricas en tiempo de ejecución. A destacar los siguientes puntos:
- Línea 17: publicación de métricas en un índice específico por aplicación de Data Lake
- Línea 28: definición de un método para publicar una métrica personalizada en Elasticsearch
- Línea 48: ejemplo de traza de log siguiendo la convención mencionada anteriormente
- Líneas 50, 51 y 54: uso del método para publicar métricas a medida
Paneles de control
Kibana permite fácilmente visualizar los datos existentes en Elasticsearch mediante la definición de distintos paneles de control donde el usuario puede combinar distintos componentes visuales que faciliten la compresión y explotación de los datos. Además, Kibana también incluye Timelion para realizar análisis de series temporales sobre tus datos.
Estos paneles de control se actualizan en tiempo prácticamente real y permiten explotar la información de una manera agregada o al detalle y en ventanas de tiempo con la granularidad que desee el usuario, desde unos pocos segundos hasta meses o años. También es posible realizar búsquedas de texto libre en todo el conjunto de logs almacenados en Elasticsearch. Además, estas visualizaciones podrán explotar los metadatos con los que se han enriquecido las trazas de log durante su encaminamiento con Logstash y que hemos explicado anteriormente.
Para ilustrar las características implementadas en esta prueba de concepto se han diseñado tres paneles de control diferentes.
Panel de control de métricas del sistema
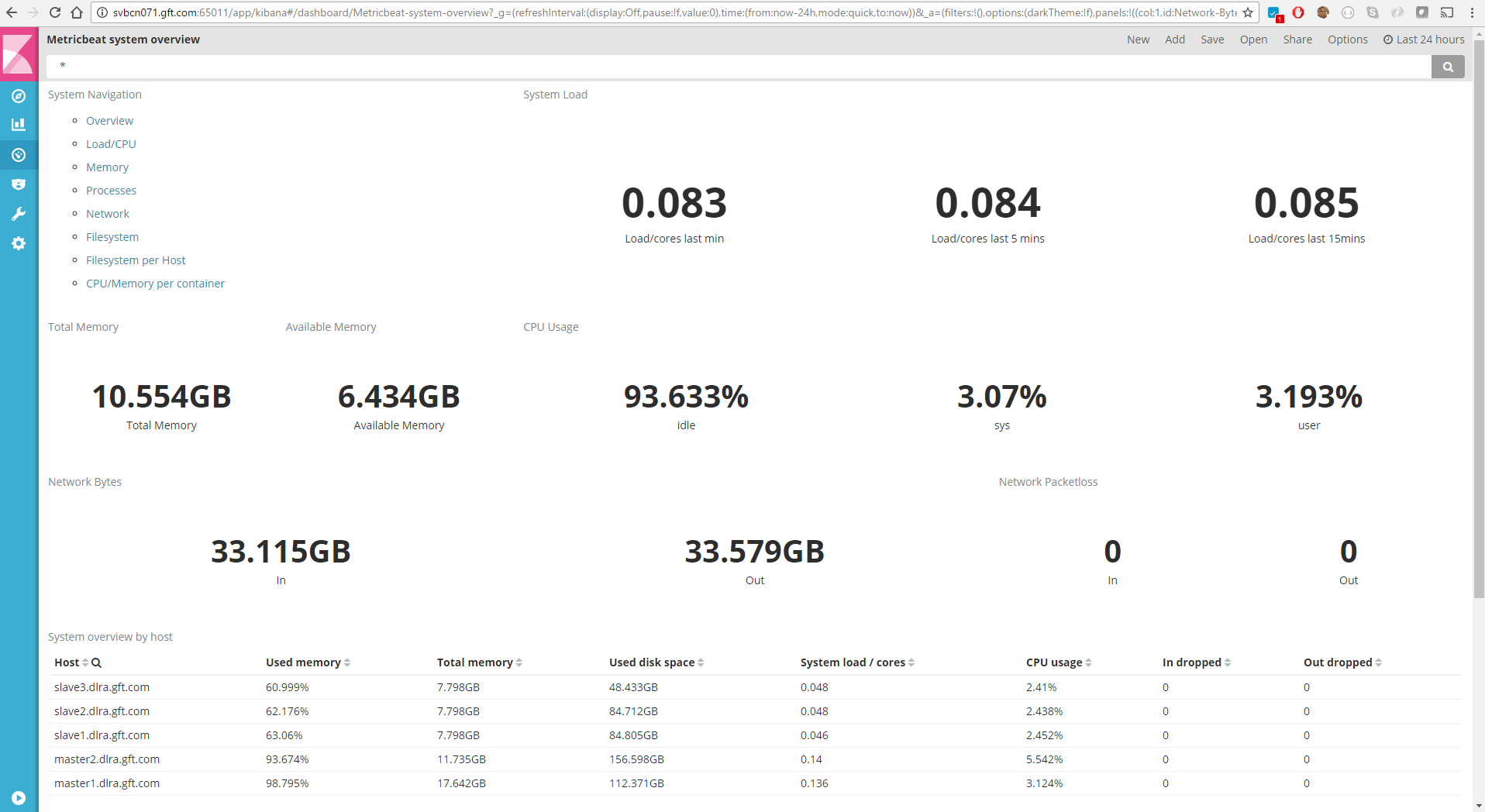
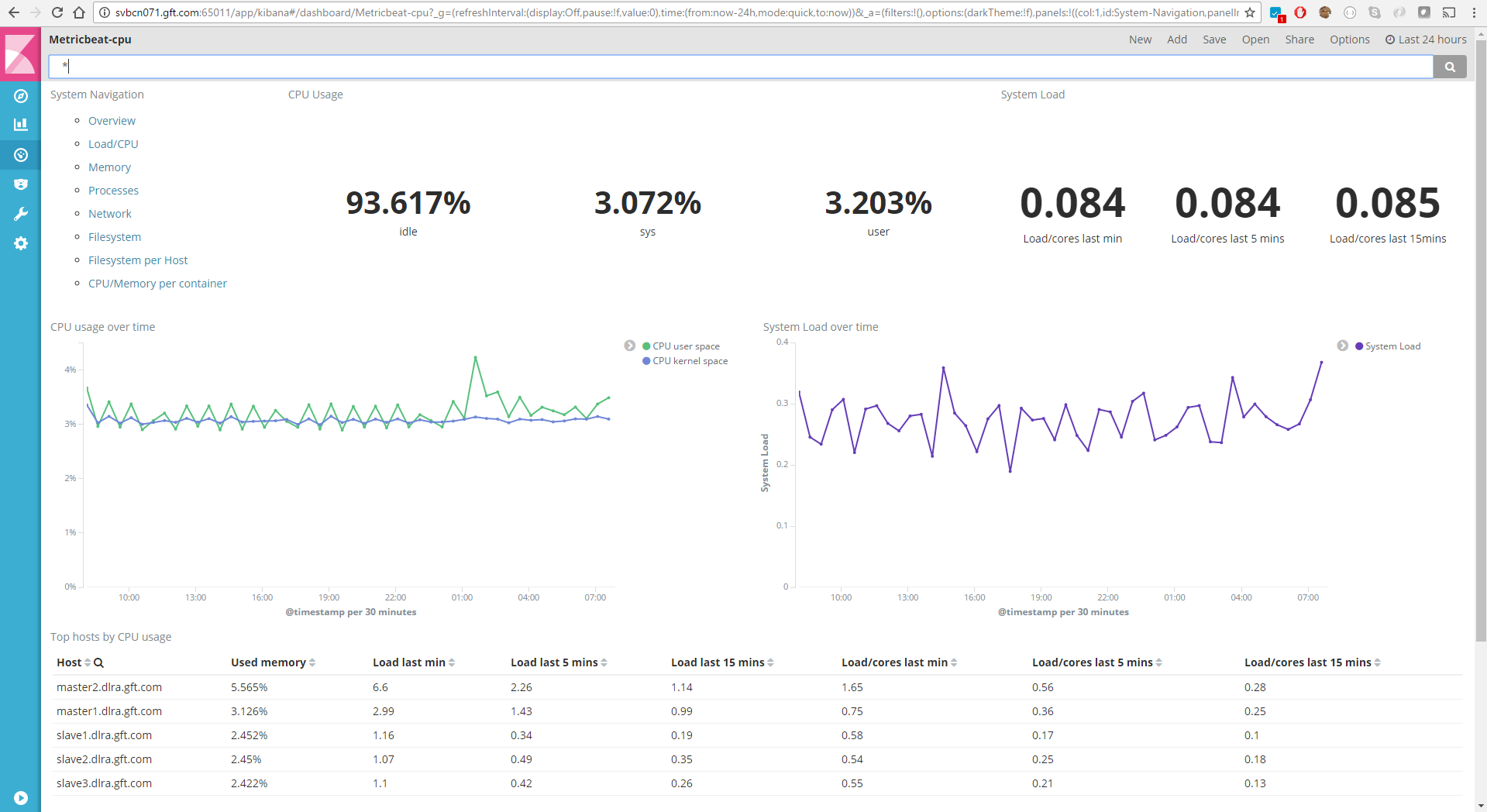
Este panel, pensado para dar soporte a los administradores de la infraestructura, incorpora componentes para la visualización de las métricas generadas por Metricbeat desde cada uno de los nodos de la infraestructura distribuida. Este panel muestra la carga de CPU, el uso de memoria, de red o del sistema de ficheros a lo largo del tiempo tanto de un nodo concreto como de toda la infraestructura, de una manera agregada.
Panel de control de vista general de las aplicaciones
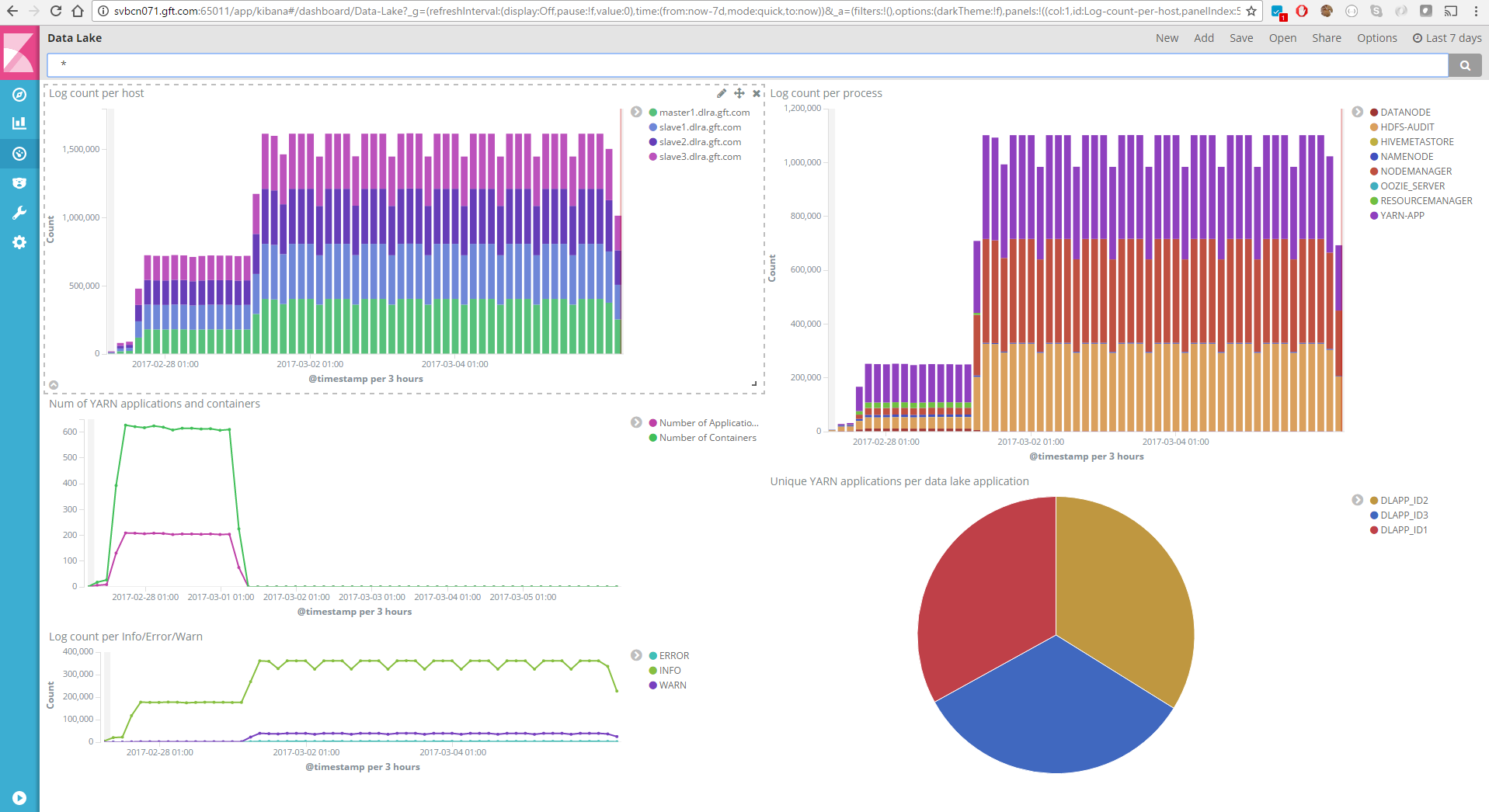
Panel de control para la explotación de los logs generados por cada una de las aplicaciones. En los tres componentes de la izquierda y de arriba abajo tenemos, a lo largo del tiempo: el número de trazas de log para cada uno de los nodos, el número de aplicaciones y contenedores de YARN utilizados, el número de trazas según su nivel de alerta (error, info o warn) de todas las aplicaciones ejecutadas en la ventana de tiempo definida por el usuario. En los dos componentes de la derecha, también de arriba abajo, tenemos: el número de trazas de log de cada uno de los servicios que conforman la plataforma Hadoop y el número de ejecuciones de distintas aplicaciones de usuario a lo largo del tiempo.
Panel de control de métricas por aplicación
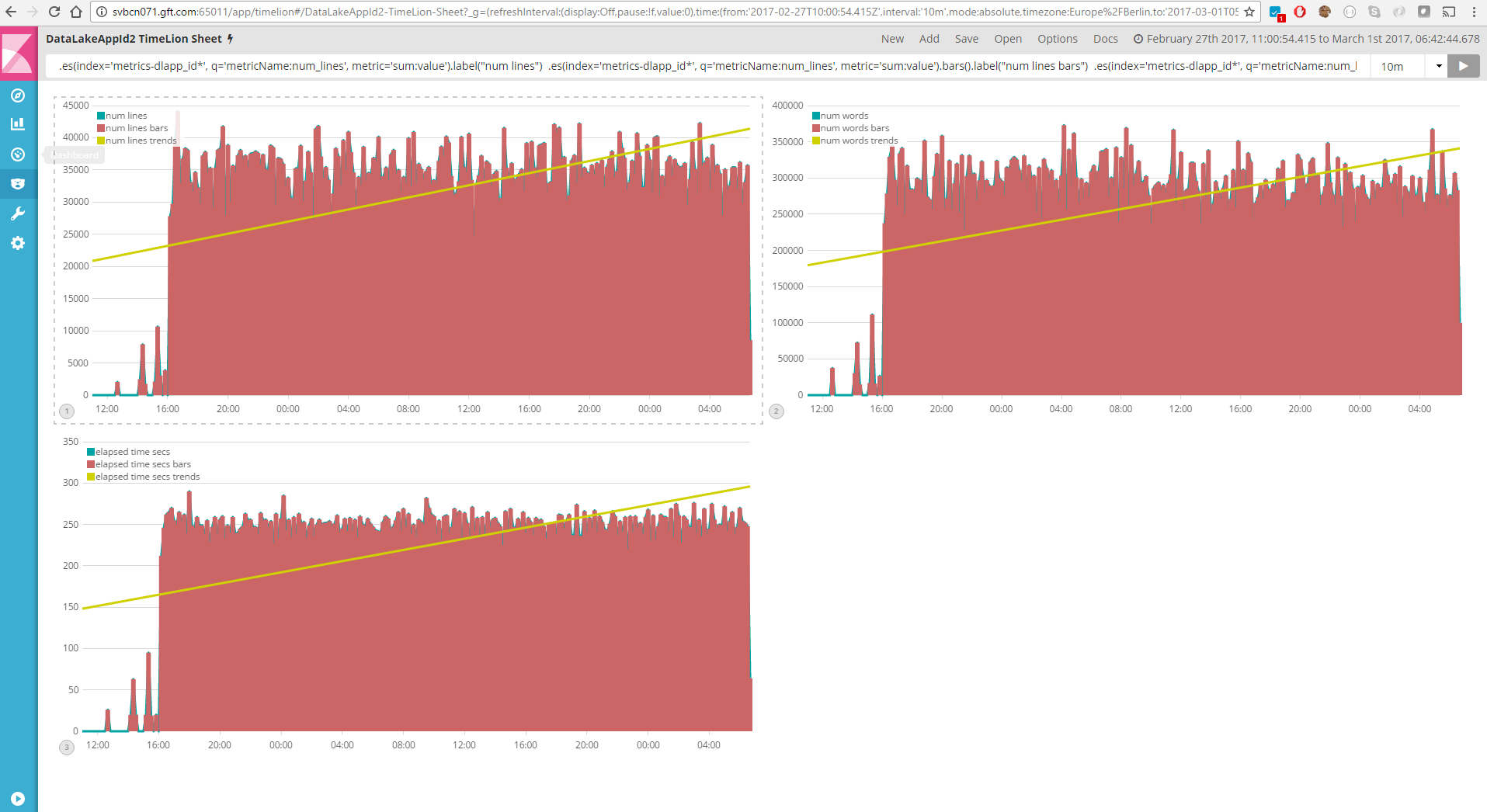
Panel de control específico de las aplicaciones para visualizar las métricas personalizadas utilizando Timelion. Obviamente, este panel de control depende completamente de la métrica que se esté visualizando. Timelion ofrece un interfaz muy amigable para que cada usuario se define sus propias visualizaciones, pudiendo incluso analizar tendencias o comparar distintas ventanas de tiempo.
Conclusiones
Un servicio de estas características permite gestionar la infraestructura de manera más eficiente y ofrece a las aplicaciones nuevas capacidades para la depuración, monitorización y análisis de su funcionamiento. Con esta implementación, más allá de mostrar un caso de uso del stack tecnológico de Elastic, podemos evaluar de una manera práctica algunos de estos beneficios.



