Cómo sustituir un Data Warehouse por SAP HANA en tres pasos
Habíamos comenzado la serie de artículos con un primer post sobre SAP HANA, donde analizamos cómo su uso puede llegar a beneficiar al sector financiero en departamentos como ventas, marketing, gestión de riesgos o contabilidad financiera. En un segundo post, explicamos cómo aprovechar las fortalezas de SAP HANA, combinándolas con las de Hadoop, con el objetivo de construir una solución integral para grandes volúmenes de datos. En el presente artículo mostramos cómo utilizar SAP HANA en lugar del tradicional Data Warehouse, y cuáles son las mejores condiciones para hacerlo con éxito.
Antes de empezar, veamos cómo se organiza un Data Warehouse estándar. En la imagen podemos observar que se utilizan los tres niveles siguientes:
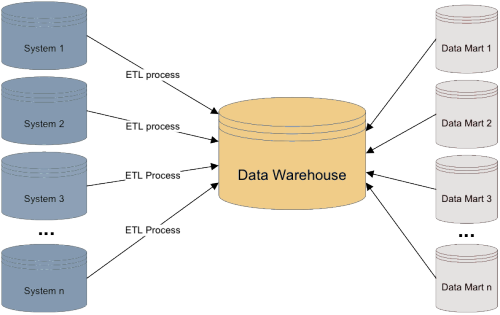
La información se extrae de las fuentes y se carga en el Data Warehouse a través de procesos de extracción, transformación y carga (ETL). A continuación, los diferentes Data Marts, que son subgrupos de datos de un data warehouse para áreas específicas, almacenan los subconjuntos de información del Data Warehouse para que puedan ser utilizados por cada uno de los departamentos o unidades de negocio de la empresa.
Considerando este proceso en su globalidad, proponemos una hoja de ruta de tres pasos para la sustitución del Data Warehouse por SAP HANA:
- El primer paso consistiría en el reemplazo de los diversos Data Marts por SAP HANA, centralizando así las diferentes vistas.
- La segunda etapa consistiría en sustituir el Data Warehouse en sí por SAP HANA, reemplazando los Data Marts por vistas analíticas o calculadas (en tiempo real) de SAP HANA y actualizando entonces los informes existentes. De esta manera estamos simplificando toda la estructura y dejando sólo las fuentes, los procesos ETL y SAP HANA.
- Por último, el tercer paso consistiría en reportar directamente los datos originales, simplificando los procesos ETL existentes. Esto permitiría obtener informes basados en datos actuales (prácticamente a tiempo real) en lugar de basarlos en copias de los datos realizadas en las horas o días previos.
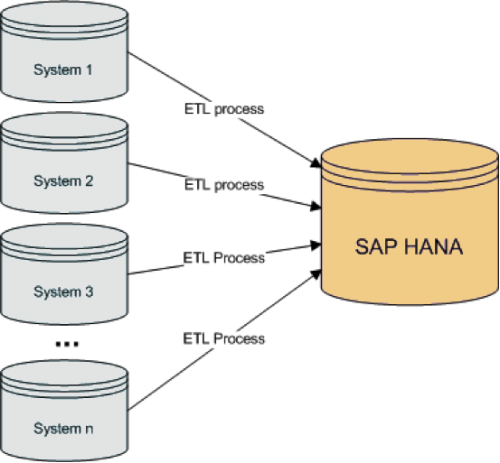
Al final de este proceso, y utilizando únicamente SAP HANA, tendríamos una solución simplificada, en la cual se extrae la información directamente de las diferentes fuentes:
Los beneficios clave que identificamos son los siguientes:
• Simplificación del número de capas con la consiguiente simplificación en el hardware y licencias requeridos
• Aceleración del proceso y obtención de la información casi en tiempo real
• Reducción de los costes de desarrollo y mantenimiento
• Disminución del tiempo de comercialización de la solución, debido a la reducción del tiempo de desarrollo.
En conclusión, hemos presentado una solución transversal, de gran simplicidad y que permite trabajar con datos reales, que debería ser considerada y valorada como una alternativa seria al Data Warehouse tradicional.



