Introduction to Machine Learning
Machine learning is about extracting knowledge from data. It is a research field at the intersection of statistics, artificial intelligence and computer science and it is also known as predictive analytics or statistical learning. The application of machine learning methods has in recent years become ubiquitous in everyday life. From automatic recommendations of which movies to watch, to what food to order or which products to buy, to personalized online radio and recognizing your friends in Machine learning algorithms that learn from input/output pairs are called supervised learning algorithms because a “teacher” provides supervision to the algorithms in the form of the desired outputs for each example that they learn from. While creating a dataset of inputs and outputs is often a laborious manual process, supervised learning algorithms are well understood and their performance is easy to measure. As stated before, we will be covering the Iris Species classification problem – a typical test case for many statistical classification techniques in machine learning
Requirements
In this project, we will need the following requirements:
- Anaconda – Python 3.6 Distribution which already has the language’s best and widely used libraries for data science (such as scipy, matplotlib, NumPy and Pandas). Anaconda Navigator also comes with Jupyter Notebook, Spyder and VSCode
- Visual Studio Code – a versatile and powerful text editor, and all-purpose IDE.
Download Anaconda (Python 3.6 distribution)
https://repo.anaconda.com/archive/Anaconda3-5.2.0-Windows-x86_64.exe
Download standalone VSCode (if you have any problems with the Anaconda’s installation):
https://code.visualstudio.com/
Creating our Machine Learning model
Configuring and using Visual Studio Code
- After installing Anaconda successfully, open Visual Studio Code and hit Ctrl + Shift + P. In the field shown above in the editor, search for “Python: Select Interpreter”
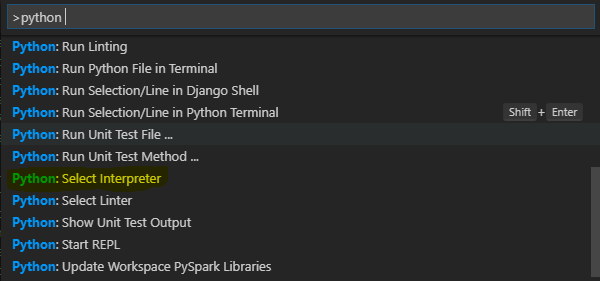
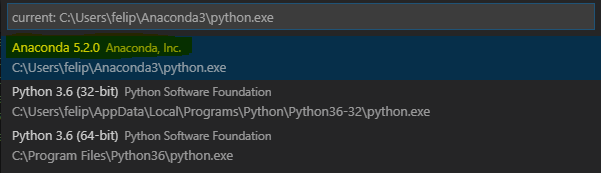
- In the following context, make sure to select Anaconda. That way, we will already have all the dependencies needed for our coding in the base Python installation.
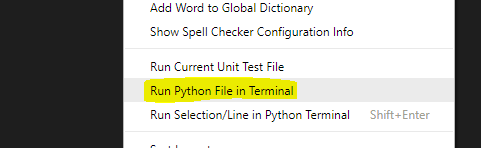
- To run your code inside VSCode, you can do one of the following:
- Right-click in the code and hit “Run Python File in Terminal”.
- Open the terminal (using Ctrl + “) and type:
- Right-click in the code and hit “Run Python File in Terminal”.
& C:/path/to/Anaconda3/python.exe “c:/path/to/file/ml-iris.py”
Understanding the scenario
Let’s assume that a hobby botanist is interested in distinguishing the species of some iris flowers that she has found. She has collected some measurements associated with each iris: the length and width of the petals and the length and width of the sepals, all measured in centimeters.
She also has the measurements of some irises that have been previously identified by an expert botanist as belonging to the species setosa, versicolor, or virginica. For these measurements, she can be certain of which species each iris belongs to. Let’s assume that these are the only species our hobby botanist will encounter in the wild.
Our goal is to build a machine learning model that can learn from the measurements of these irises whose species is known, so that we can predict the species for a new iris.

An example of iris flower and the features of our model

Images of the three classes of Iris considered in this model
Importing the libraries
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
First of all, let’s import the modules as listed above:
- SkLearn is a pack of Python modules built for data science applications (which includes machine learning). Here, we’ll be using three particular modules:
- load_iris: The classic dataset for the iris classification problem. (NumPy array)
- train_test_split: method for splitting our dataset.
- KNeighborsClassifier: method for classifying using the K-Nearest Neighbor approach.
- NumPy is a Python library that makes it easier to work with N-dimensional arrays and has a large collection of mathematical functions at disposal. It’s base data type is the “numpy.ndarray”.
Building our model
Because we have measurements for which we know the correct species of iris, this is a supervised learning problem. In this problem, we want to predict one of several options (the species of iris). This is an example of a classification problem. The possible outputs (different species of irises) are called classes. Every iris in the dataset belongs to one of three classes, so this problem is a three-class classification problem. The desired output for a single data point (an iris) is the species of this flower. For a particular data point, the species it belongs to is called its label.
As already stated, we will use the Iris Dataset already included in scikit-learn.
iris_dataset = load_iris()
Now, let’s print some interesting data about our dataset:
print(“Target names: {}”.format(iris_dataset[‘target_names’]))
print(“Feature names: {}”.format(iris_dataset[‘feature_names’]))
print(“Type of data: {}”.format(type(iris_dataset[‘data’])))
Output:
![]()
Remember that the individual items are called samples in machine learning, while their properties are called features. The shape of the data array is the number of samples multiplied by the number of features. This is a convention in scikit-learn, and your data will always be assumed to be in this shape. In this case: our data has 150 samples with 4 features each (sepal length (cm), sepal width (cm), petal length (cm), petal width (cm)).
print(“Shape of data: {}”.format(iris_dataset[‘data’].shape))
Output:
![]()
The target array contains the species of each of the flowers that were measured, also as a NumPy array. This array is composed of numbers from 0 to 2.
The meaning of those numbers are directly related to our target names:
- setosa (0)
- versicolor (1)
- virginica(2)
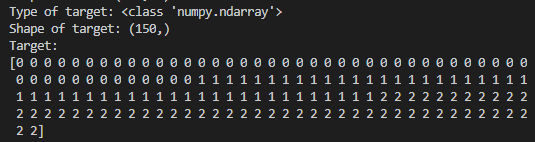
print(“Type of target: {}”.format(type(iris_dataset[‘target’])))
print(“Shape of target: {}”.format(iris_dataset[‘target’].shape))
print(“Target:\n{}”.format(iris_dataset[‘target’]))
Output:
To assess the model’s performance, we show it new data (data that it hasn’t seen before) for which we have labels.
This is usually done by splitting the labeled data we have collected (here, our 150 flower measurements) into two parts. One part of the data is used to build our machine learning model, and is called the training data or training set. The rest of the data will be used to assess how well the model works; this is called the test data, test set, or hold-out set.
scikit-learn contains a function that shuffles the dataset and splits it for you: the train_test_split function.
This function extracts 75% of the rows in the data as the training set, together with the corresponding labels for this data. The remaining 25% of the data, together with the remaining labels, is declared as the test set.
The arguments can be interpreted as: train_test_split(samples, features, random seed) – and it returns 4 datasets.
X_train, X_test, y_train, y_test =
train_test_split(iris_dataset[‘data’],iris_dataset[‘target’],
random_state=0)
Printing the shape of the train samples, along with their respective targets:
print(“X_train shape: {}”.format(X_train.shape))
print(“y_train shape: {}”.format(y_train.shape))
Output:
![]()
Same for the test samples
print(“X_test shape: {}”.format(X_test.shape))
print(“y_test shape: {}”.format(y_test.shape))
Output:
![]()
Now we can start building the actual machine learning model. There are many classification algorithms in scikit-learn that we could use. Here we will use a k-nearest neighbors classifier, which is easy to understand.
Building this model only consists of storing the training set. To make a prediction for a new data point, the algorithm finds the point in the training, then it assigns the label of this training point to the new data point.
The k in k-nearest neighbors signifies that instead of using only the closest neighbor to the new data point, we can consider any fixed number k of neighbors in the training (for example, the closest three or five neighbors). Then, we can make a prediction using the majority class among these neighbors. Here, we will use one neighbor.

Illustration of the K-Nearest Neighbor approach given K=1 and K=3
All machine learning models in scikit-learn are implemented in their own classes, which are called Estimator classes. The k-nearest neighbors classification algorithm is implemented in the KNeighborsClassifier class in the neighbors module.
knn = KNeighborsClassifier(n_neighbors=1)
To build the model on the training set, we call the fit method of the knn object, which takes as arguments the NumPy array X_train containing the training data and the NumPy array y_train of the corresponding training labels:
knn.fit(X_train, y_train)
We can now make predictions using this model on new data for which we might not know the correct labels.
Imagine we found an iris in the wild with a sepal length of 5 cm, a sepal width of 2.9 cm, a petal length of 1 cm, and a petal width of 0.2 cm.
What species of iris would this be? We can put this data into a NumPy array, again by calculating the shape—that is, the number of samples (1) multiplied by the number of features (4):
X_new = np.array([[5, 2.9, 1, 0.2]])
print(“X_new.shape: {}”.format(X_new.shape))
Output:
To make a prediction, we call the predict method of the knn object:
prediction = knn.predict(X_new)
print(“Prediction: {}”.format(prediction))
print(“Predicted target name: {}”.format(iris_dataset[‘target_names’][prediction]))
Output:![]()
Our model predicts that this new iris belongs to the class 0, meaning its species is setosa. But how do we know whether we can trust our model? We don’t know the correct species of this sample, which is the whole point of building the model.
Measuring the model
This is where the test set that we created earlier comes in. This data was not used to build the model, but we do know what the correct species is for each iris in the test set. Therefore, we can make a prediction for each iris in the test data and compare it against its label (the known species).
We can measure how well the model works by computing the accuracy, which is the fraction of flowers for which the right species was predicted (number which we can calculate using the NumPy “mean” method, comparing both datasets):
y_pred = knn.predict(X_test)
print(“Test set predictions:\n {}”.format(y_pred))
print(“Test set score (np.mean): {:.2f}”.format(np.mean(y_pred == y_test)))
Output:

We can also use the score method of the knn object, which will compute the test set accuracy for us:
print(“Test set score (knn.score): {:.2f}”.format(knn.score(X_test, y_test)))
Output:
![]()
For this model, the test set accuracy is about 0.97, which means we made the right prediction for 97% of the irises in the test set. Under some mathematical assumptions, this means that we can expect our model to be correct 97% of the time for new irises.
For our hobby botanist application, this high level of accuracy means that our model may be trustworthy enough to use.
Summary
Albeit simple, the iris flower classification problem (and our implementation) is a perfect example to illustrate how a machine learning problem should be approached and how useful the outcome can be to a potential user.
For more resources about the topic, I recommend the book Introduction to Machine Learning with Python: A Guide for Data Scientists, by Andreas C. Müller, which has many hands-on tutorials for machine learning scenarios.
Other awesome learning resources are:
- Code Academy – Machine Learning Fundamentals
- Udemy – Machine Learning A-Z™: Hands-On Python & R In Data Science
- O’Reilly – Large collection of Machine Learning Books


