Spanner – A revolution for financial services
Anyone familiar with transactional database systems knows that management of a distributed DB setup can be painful. Despite industry progress, some challenges still keep DB admins awake at night. Scaling databases to accommodate increasing load, ensuring high availability without sacrificing accessibility and making data consistent in a scalable and highly available system are not easy problems to solve.
Such challenges are often addressed with bespoke sharding implementations or NoSQL alternatives.
For the former, think of YouTube, Facebook, Twitter and others. It is not neccessarily the financial industry, but the common denominator for these companies is global operations and likely surges of ever-increasing traffic. Bespoke solutions have reputation of being very complex and only a few companies can justify the cost of building them. The latter, NoSQL, promises to scale, but usually smuggles the “eventual consistency” term which for many applications is not an option.
Google Cloud Spanner
The promise of Spanner is the best of both SQL and NoSQL worlds. It is a database service that provides its users with: No setup – everything runs on Google infrastructure, automatic sharding, zero-downtime upscaling, five nines availability and SQL interface on top of it all. It “spans” as many nodes as you need it to and despite being a highly available distributed system, it provides very strong transactional consistency guarantees. There are major practical advantages of its design.
In the first place, Spanner allows to increase the amount of available storage and CPU power without downtime. External consistency is maintained all the time, meaning that transactions are handled as if they were executed sequentially. There may be multiple machines and different datacentres involved, but Spanner still behaves as a DB server running on a single box. It is not easy to upgrade CPU or storage with a single machine without downtime, though.
Secondly, Spanner replicas can be placed close to all datacentres a solution needs. This allows to achieve low network latencies from different places (think continents). Still with the “single box” experience. Low latencies and quick replication is achieved with Spanner’s access to Google network infrastructure.
Taste of benchmarks
GFT is currently running a series of performance tests for Spanner. There are already enough insights for a separate article, but for now, please find a single performance graph showing upscaling of Spanner under heavy load. During the test, there were ~6000 write transactions/s. The change is from 3 to 7 nodes @15.29.19 which is depicted with the grey line. NYK/TKY/LDN are three distinct sources of load simulating a global access scenario.
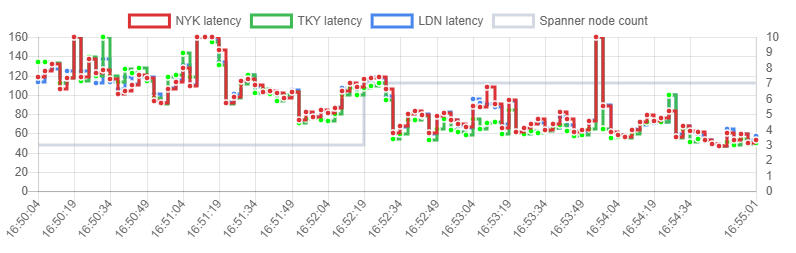
It took Spanner around half a minute to cut query latencies from >100ms to

Google Console configuration ties throughput and capacity together, which means that increasing the number of nodes works both for solving the performance as well as out-of-space issues.
What about developers?
What’s in it for you, when you are a developer? Well, as one could already guess, the problems Spanner solves are ones of Ops rather than Devs. The good news is that Spanner supports SQL queries and provides API for a few popular languages, Java (JDBC), Python, Go and Node.js included. I only had the chance to try the Java one and it really is approachable.
Despite the lack of DML, SQL compatibility is great, although there are some issues one needs to be aware of. Please see the next section.
Gotchas
Back in 2012, Joel Spoolsky wrote “All non-trivial abstractions, to some degree, are leaky“. Spanner is definitely non-trivial. Most of its intricacies are not visible to users, but still, one just needs to be aware of the fact that there are lots of things happening behind the scenes and they may influence performance and impose some limitations on data model design.
For instance, Spanner’s ability to scale depends on proper schema design and one of anti-patterns is monotonic keys, something most developers are very much used to. The scaling algorithm applies sharding automatically, which means there is no full control over what and when Spanner decides to reshuffle its data. In a way, this resembles Java’s just-in-time compiler that is able to change performance characteristics while a program is running, which is a great thing, but it also means that some performance metrics may change somewhat unexpectedly.
There are also a few limitations, like the optimizer being somehow simplistic and the lack of DML. The optimizer issue is especially annoying as it leads to (among others) extensive use of index hinting, but these are most likely due to Spanner’s relative young age and will hopefully be fixed soon.
What’s next
Spanner is indeed a big thing for GFT. It basically means we are able to provide our clients with cost-effective solutions that up till now were too expensive or too complex to implement. Rather than being a new cool framework for data storage, it is an attempt to solve generation-old challenges financial institutions are all too familiar with.
Please stay tuned for the next article in the Spanner series, where I will be taking a closer look at its performance characteristics, especially with upcoming multi-regional configuration.
GFT and Google are running the Spanner showcase event at 28.09 in London. For more details, visit: https://events.withgoogle.com/google-cloud-spanner-a-revolution-for-financial-services/
Further links:
Andrew Rositer – Google Cloud Spanner: The next big transformation in financial services?
Nick Weisfeld – Cloud database technology can no longer be ignored in financial services
Quizlet testing – https://quizlet.com/blog/quizlet-cloud-spanner

